Introduction, statistics review
Class overview
Machine learning & data-driven modeling in bioengineering
Lecture
- Tuesdays/Thursdays, 8–9:50 am
- Boelter 2760
Lab
- Varies by section—check the course schedule.
Lecture Slides
- Lecture slides will be posted on the course website.
- Finalized by the night before so you can print them out if you want.
- The slides are not everything, but will include space to fill out missing elements during class.
Textbook / Other Course Materials
- There is no textbook for this course.
- We will post related readings prior to each lecture.
- These will either broaden the scope of material covered in class or provide critical background.
- We will make it clear if the material is more than optional.
Attendance
- We expect students to come to the lectures and discussion sessions.
- The lecture is recorded via BruinCast to accommodate personal circumstances.
- However, if the attendance level is too low, we will stop releasing the video.
Support / Office Hours
Prof. Meyer
- Thursday, 10–10:50 am in Engineering V 4121G
- I will usually stick around after class and am happy to answer questions
Prof. Tanigawa
- Tuesday, 10–10:50 am in Engineering V 5121E
TAs
- By appointment
- Will have regular times set up soon
Campuswire
- Allows for quick help from us, the TAs, and the LAs
Learning Goals:
By the end of the course you will have an increased understanding of:
- Critical Thinking and Analysis: Understand the process of identifying critical problems, analyzing current solutions, and determining alternative successful solutions.
- Engineering Design: Apply mathematical and scientific knowledge to identify, formulate, and solve problems in the chosen design area.
- Computational Modeling: Apply computational tools to solve and optimize engineering problems.
- Communicate Effectively: Learn how to give an effective presentation. Understand how to communicate progress orally and in written reports.
- Manage and Work in Teams: Learn to work and communicate effectively with peers to attain a common goal.
Practical Learning Objectives
By the end of the course you will learn how to:
- Identify whether and how a problem can be solved by machine learning.
- Determine the prerequisites to applying the method.
- Implement different techniques to solve the scientific/engineering task.
- Critically assess machine learning results.
Grade Breakdown
- 25%
- Final Project
- 25%
- Lab Assignments
- 40%
- Midterms 1 & 2
- 10%
- Class Participation
Labs
Sessions
- These are mandatory sessions.
- You will have an opportunity to get started on each week’s implementation and/or work on your project.
Computational Labs
- You will implement what we have learned using real data from studies.
- These labs reinforce the material through hands-on practice.
- They are meant to help you become comfortable applying the material.
- Document your effort, get started early, and seek help in office hours, in lab, or on Campuswire.
- Your lowest lab grade will be automatically dropped.
AI usage in Computational Labs
- UCLA provides access to Generative AI (GenAI) tools
- https://dts.ucla.edu/initiatives/ai/available-tools
- GenAI tools help you perform the tasks you’re familiar with, but mere reliance on them without critical assessment of their output may block your learning process
- We will ask you to (1) declare your use of those tools and (2) explain how you verified the outputs in assignments
Project
- You will take data from a scientific paper, and implement a machine learning method using best practices.
- A list of papers and data repositories is provided on the website as suggestions.
- Absolutely go find ideas that interest you!
- More details to come.
- First deadline will be in week 3 to pick a project topic.
Exams
- We will have midterm exams on weeks 5 and 9.
- You will have a final project in lieu of a final exam.
Keys to Success
- Participate in an engaged manner with in-class and take-home activities.
- Turn assignments in on time.
- Work through activities, reading, and problems to ensure your understanding of the material.
If you do these three things, you will do well.
Introduction
How do we need to learn about the world?
- What is a measurement?
- What is a model?
Three things we need to learn about the world
- Measurements (data)
- Models (inference)
- Algorithms
Area of Focus
What we will cover spans a range of fields:
- Engineering (the data)
- Statistics (the model)
- Computational techniques (the algorithms)
Why do we need models to learn about the world?
Can a biologist fix a radio?

Lazebnik et al, Cancer Cell, 2002
Reverse-engineering a radio

Lazebnik et al, Cancer Cell, 2002
Formal circuit representation
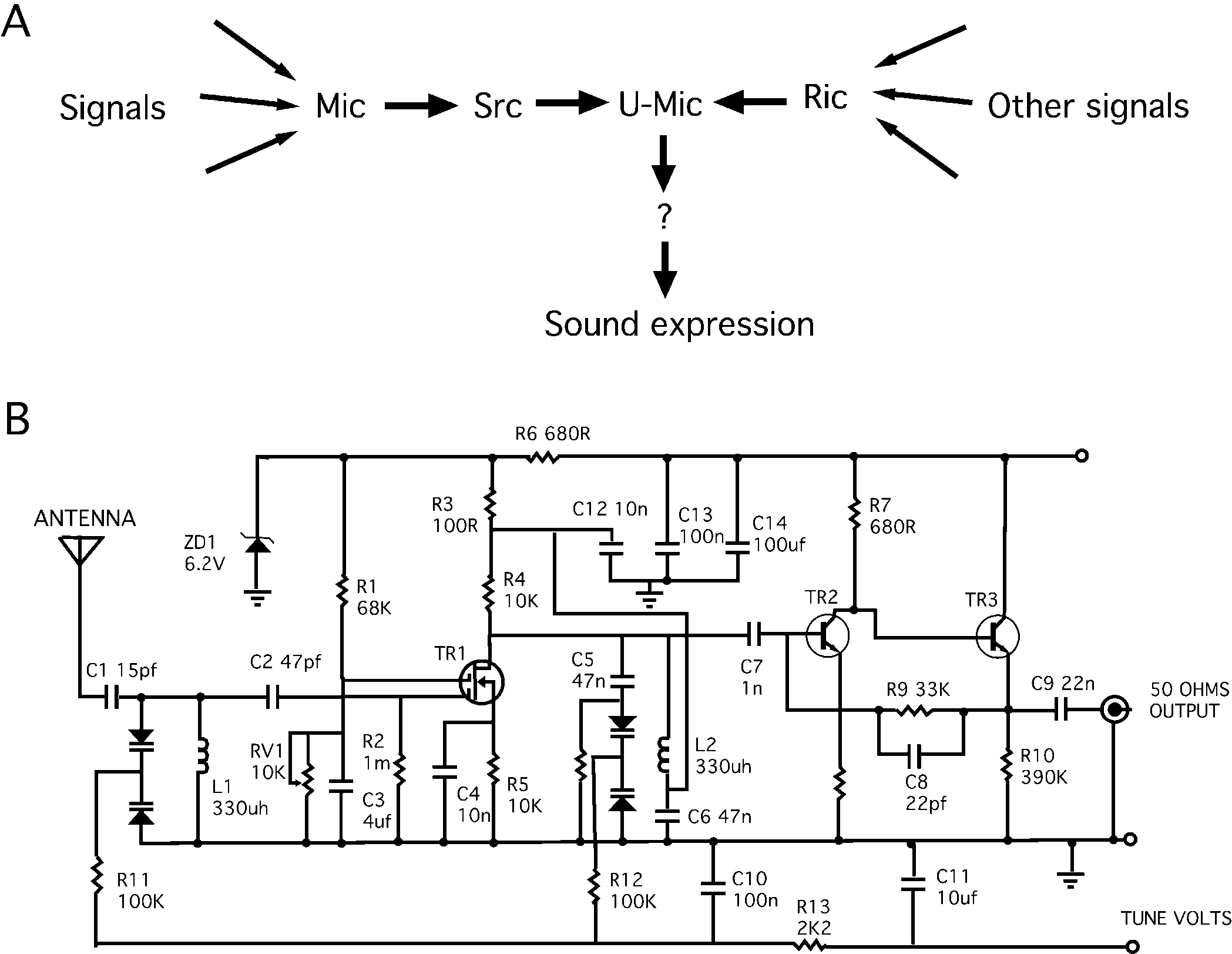
Lazebnik et al, Cancer Cell, 2002
Comparisons
- Multiscale nature
- Biology operates on many scales
- Same is true for electronics
- But electronics employ compartmentalization/abstraction to make understandable
- Component-wise understanding
- Only provides basic characterization
- Leads to “context-dependent” function
- Standardized formal language
- Anyone can unambiguously understand the system
- It enables quantitative analyses, including modeling
Machine learning outperforms humans for some tasks
Thompson et al. Proc. 1st Int. Conf. on Evolvable Systems, 1996
The FPGA hardware setup to test a genetic algorithm (GA)
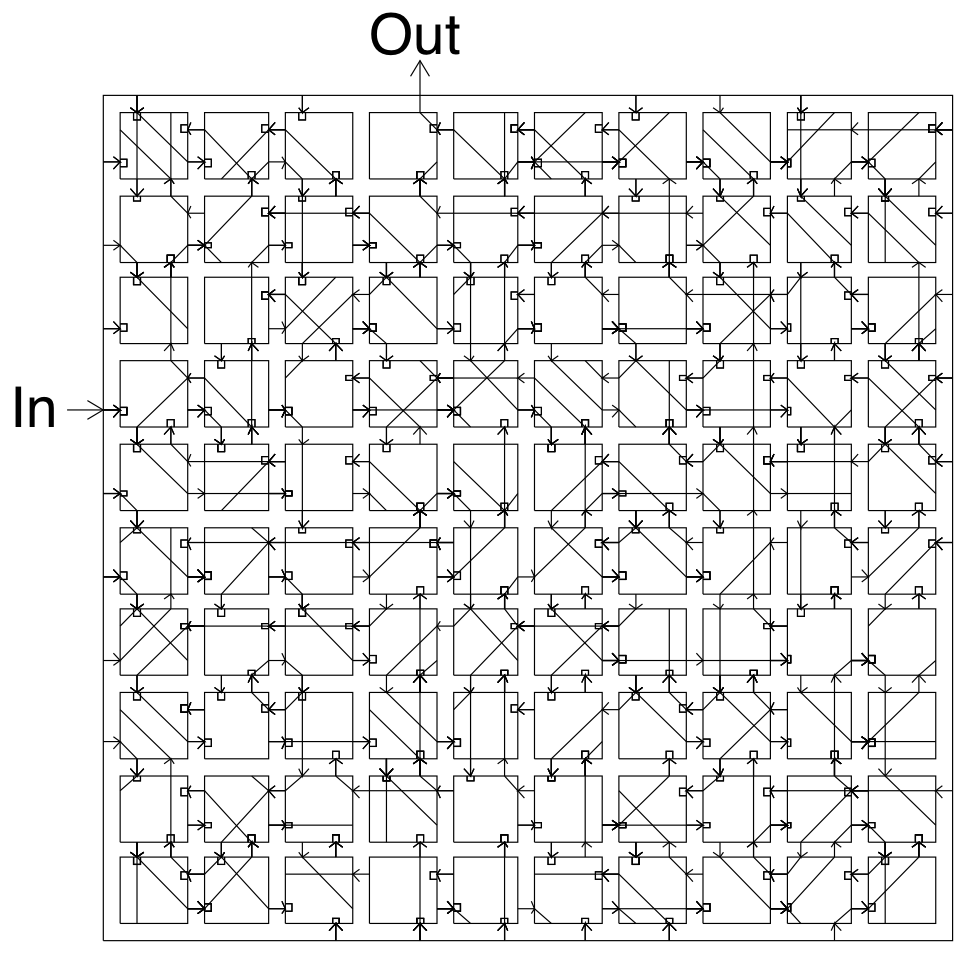
Thompson et al. Proc. 1st Int. Conf. on Evolvable Systems, 1996
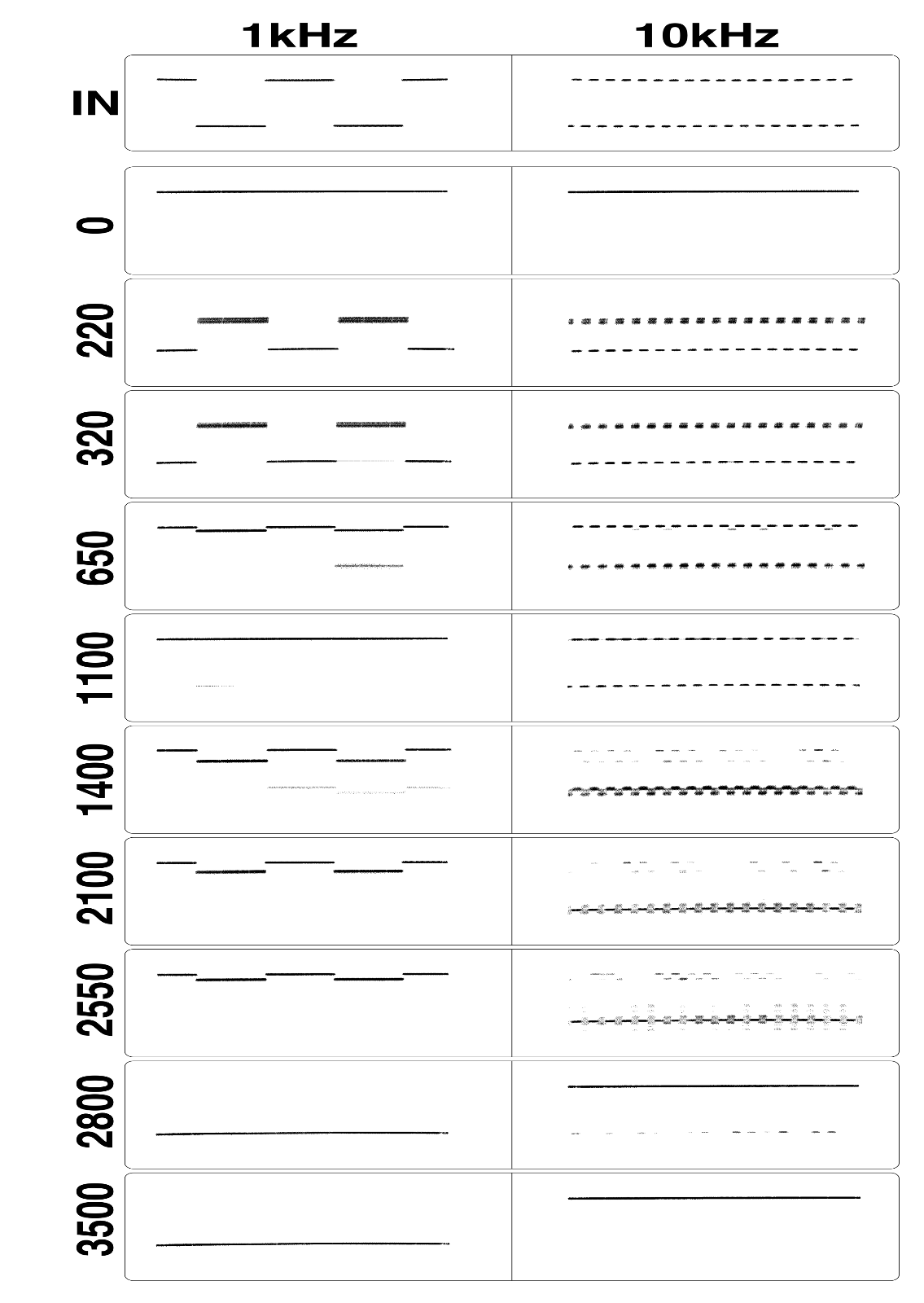
The maximum and minimum fitness and genetic convergence
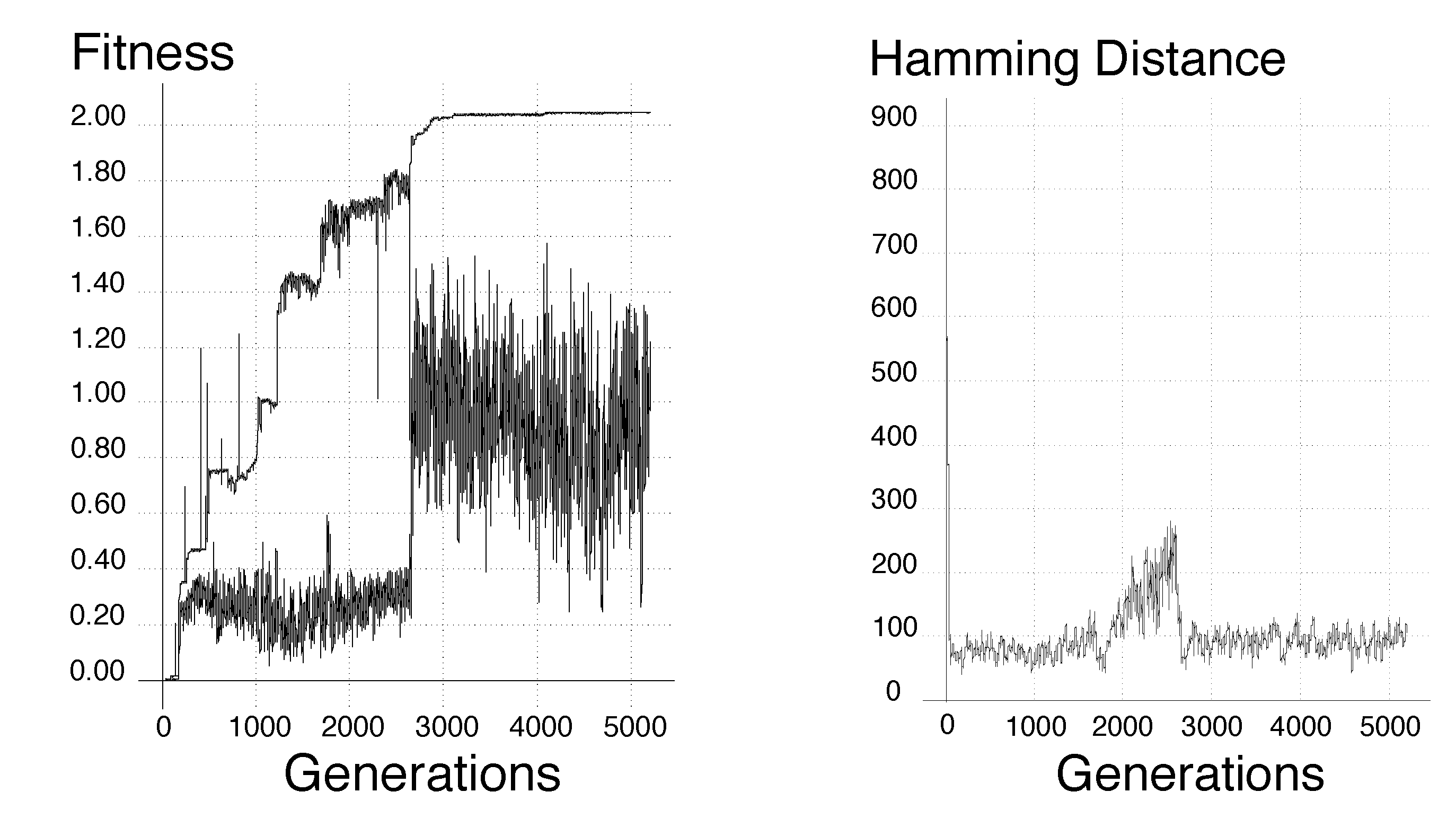
Thompson et al. Proc. 1st Int. Conf. on Evolvable Systems, 1996
Learned circuit
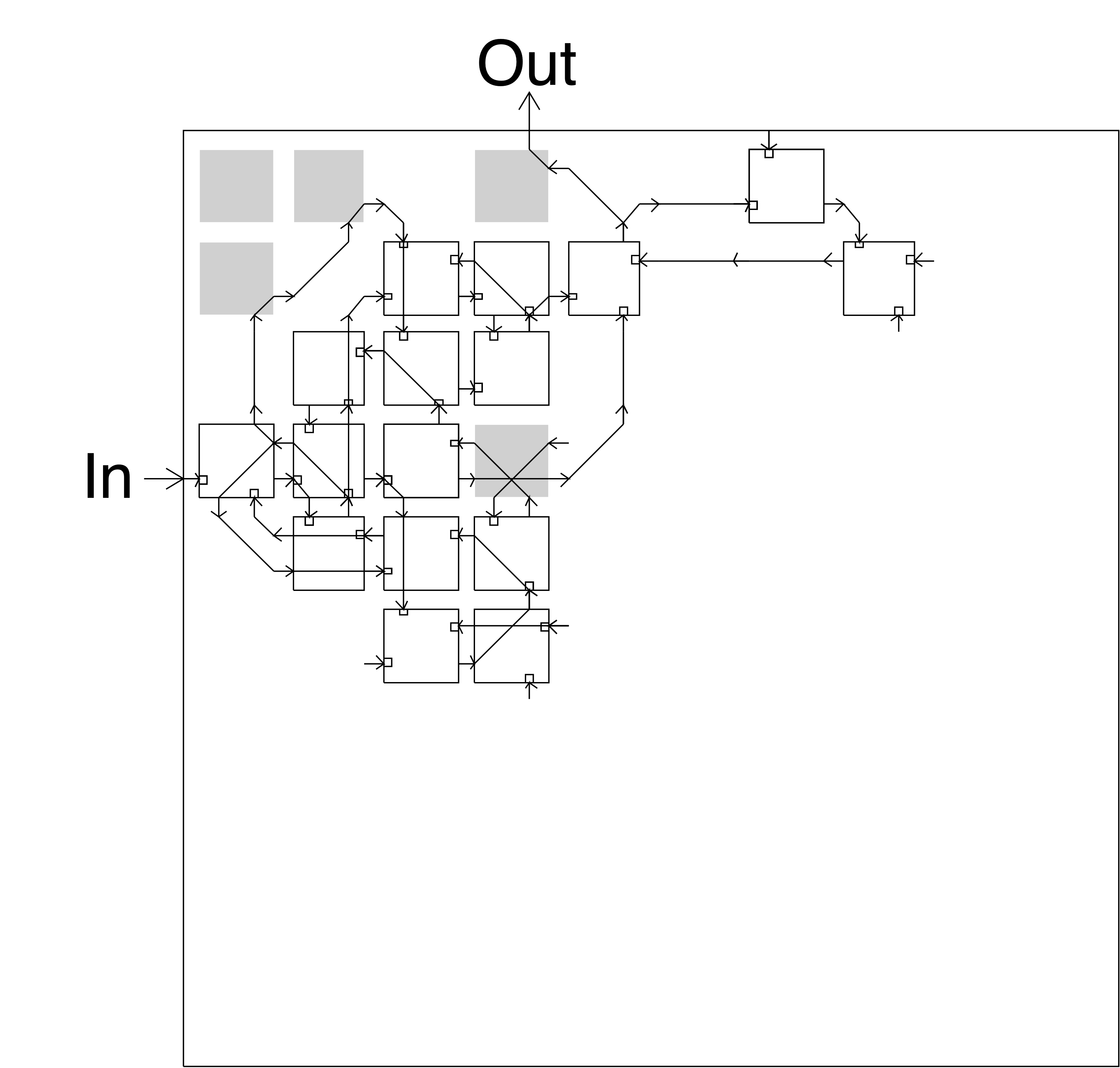
Thompson et al. Proc. 1st Int. Conf. on Evolvable Systems, 1996
Basic Statistical Concepts
Data
- What is a variable?
- What is an observation?
- What is N?
Types of variables
- Categorical
- Numerical/continuous
- Ordinal
Probability
- Probability indicates the chance of an event within a broader set of outcomes.
- \(X\): random variable with possible outcomes \(x \in \Omega\)
- First axiom: \(p(x) \geq 0\)
- Second axiom: \(\sum_{x}p(x) = 1\)
- Third axiom: \(p(A \cup B) = p(A) + p(B)\) for mutually exclusive events \(A\) and \(B\).
Examples
Dice rolling example
- Consider rolling a dice
- The possible outcomes (\(\Omega\)) are \(\{1, 2, 3, 4, 5, 6\}\)
- They are mutually exclusive.
- Let’s verify the three axioms.
- \(p(X = i) \geq 0\) for all \(i \in \Omega\).
- \(\sum_{i = 1}^6 p(X = i) = 1\).
- \(p(X = i \cup X = j) = p(X = i) + p(X = j)\) if \(i \neq j\).
Coin toss example
A set of trials: HTHHHTTHHTT
Two possibilities:
- Fair coin (heads 50%, tails 50%)
- Biased (heads 60%, tails 40%)
Probability distributions
We’ve already been talking about these! Distributions describe the range of probabilities that exist for all possible outcomes.
Other probability concepts
- Joint probability
- In a multivariate probability space, the distribution for more than one variable. \(p(X, Y)\).
- Conditional probability
- The measure of an event given that another event has occurred. \(p(X \mid Y) = p(X, Y)/p(Y)\).
- Marginal distribution
- The probability distribution regardless of other observations/factors. \(p(X) = \sum_{Y}p(X, Y)\).
- Complementary event
- The probability of an event not occurring. \(p(X^c) = 1 - p(X)\).
Normal distributions
- Also known as Gaussian Distributions
- Two model parameters
- \(\mu\): center of the distribution
- \(\sigma\): standard deviation
- \(\sigma^2\): variance
\[f(x)={\frac {1}{\sqrt {2\pi \sigma ^{2}}}}e^{-{\frac {(x-\mu )^{2}}{2\sigma ^{2}}}}\]
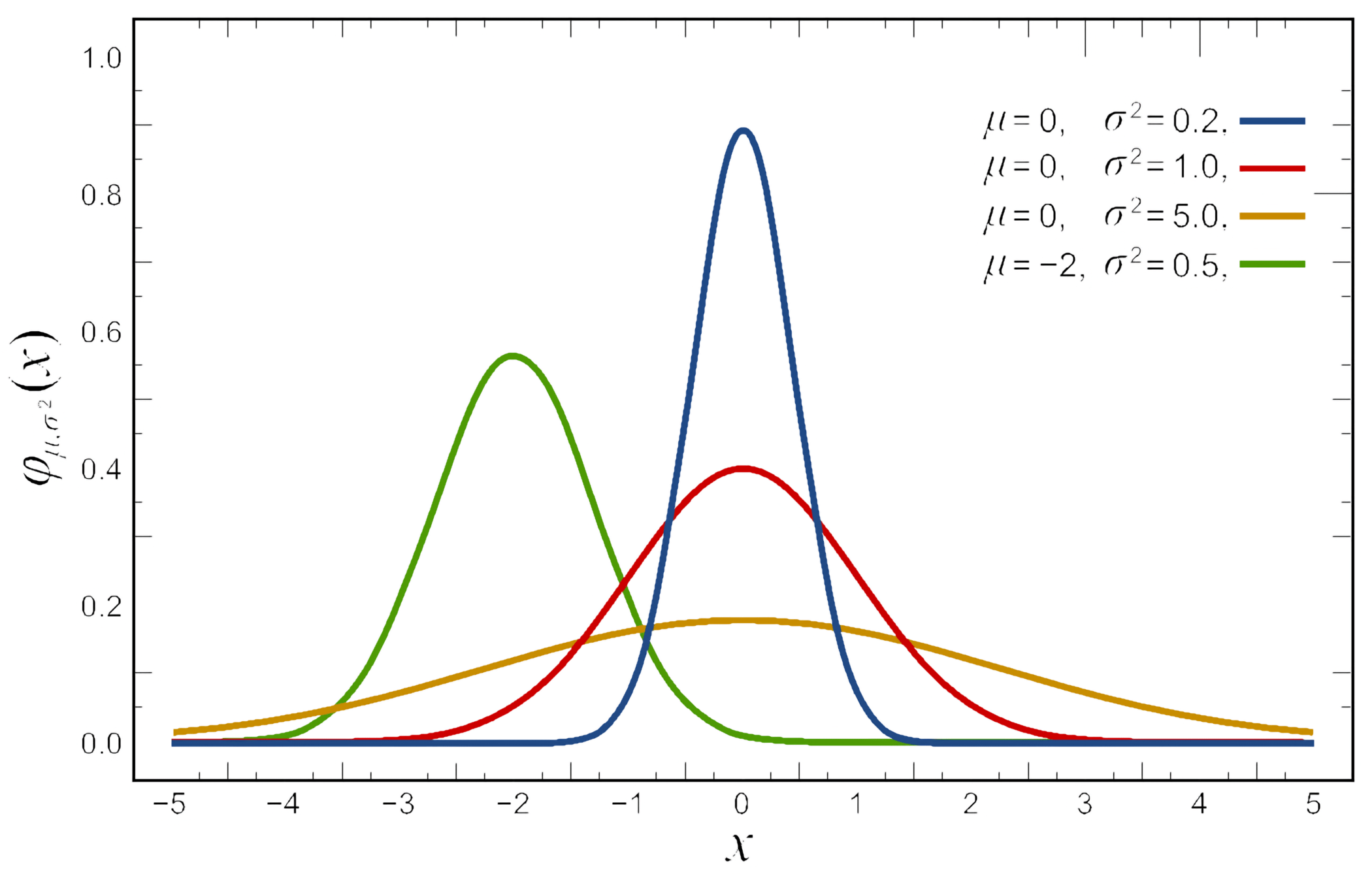
Standard normal distribution
For a standard normal distribution (\(\mu = 0\), \(\sigma = 1\)):
\[f(x)=\frac{1}{\sqrt{2\pi}}\; e^{-\frac{x^2}{2}}\]
Area between:
- One standard deviation: 68%
- Two standard deviations: 95%
- Three standard deviations: 99.7%
You can normalize any normal distribution to the standard normal.
Other commonly used distributions
- Normal distribution: common for many naturally observed variables; often summarized by its mean and standard deviation.
- Poisson distribution: counts events in a fixed interval.
- Exponential distribution: describes the time between events in a Poisson process.
- Gamma distribution: often used for modeling waiting times and in Bayesian statistics.
- Bernoulli distribution: a binary outcome, like a coin flip.
- Binomial distribution: the number of successes in a sequence of Bernoulli trials.
- Multinomial distribution: a generalization of the binomial distribution for more than two states.
Distribution moments
The moments of a distribution describe its shape: \[\mu_{n}=\int_{-\infty}^{\infty}(x-c)^{n}\,f(x)\,\mathrm{d} x\]
- Mean (\(n=1\)), variance (\(n=2\)), skewness (\(n=3\)), kurtosis (\(n=4\))
- Essential properties to determining how data will behave during analysis:
- How might your measurements need to change with changes in variance?
- What are these values for a normal distribution?
Sample statistics
Sampling distributions
If we sampled a finite number of times (let’s say sample size of \(n=3\)), we could build a sampling distribution of the statistics (e.g., one for the sample mean and one for the sample standard deviation).
General properties of sampling distributions:
- The sampling distribution of a statistic often tends to be centered at the value of the population parameter estimated by that statistic
- The spread of the sampling distributions of many statistics tends to grow smaller as sample size \(n\) increases
- Central Limit Theorem: As \(n\) increases, the sampling distribution of the sample mean tends toward normality. \(\bar{X} \approx N\left(\mu, \frac{\sigma^2}{n}\right)\)
Sample mean
- This means that as \(n\) increases, the sample mean \(\bar{X}\) is a better estimate of \(\mu\).
- The standard error is the standard deviation of the sample mean.
- When a population distribution is normal, the sampling distribution of the sample statistic is also normal, regardless of \(n\).
- And the central limit theorem states that the sampling distribution can be approximated by a normal distribution when the sample size, \(n\), is sufficiently large.
- A common rule of thumb is that \(n=30\) is sufficiently large, but there are times when smaller \(n\) will suffice. Greater \(n\) may be required with higher skewness.
Hypothesis Testing
In hypothesis testing, we state a null hypothesis that we will test; if the p-value is less than a chosen threshold, then we reject it.
For example:
- \(H_0\): A particular set of points comes from a normal distribution with mean \(\mu\) and variance \(\sigma^2\).
- \(H\): Two sets of observations were sampled from distributions with different means.
When we do an experiment, we typically take a sampling of several observations, to be more certain of the result.
T-distribution
The t-distribution with \(n-1\) degrees of freedom is useful for comparing means with small sample size \(n\) and unknown population variance.
- \(H_0\): Assume \(\mu=\mu_0\) then calculate t. \[t = \frac{\overline{x} - \mu_0}{s/\sqrt{n}}\]
- You can think of \(t\) as \(z/s\), where it is sensitive to the magnitude of the difference from the null and scaled to control for the spread.
- When comparing two means under the equal-variance assumption: \[t=\frac{\bar{X}_1-\bar{X}_2}{s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}\]
- Here, \(s_p\) is the pooled standard deviation.
Effect size
- The scalar factor scales the t-value
- For normal data, the standard error scales as \(1 / \sqrt{n}\)
- p-values can become significant even with a small difference in means
- For normal data, the standard error scales as \(1 / \sqrt{n}\)
- Exercise caution and report the effect size
- For example, a 1% or 50% difference in the means
Kolmogorov-Smirnov test
- Comparison of an empirical distribution function with the distribution function of the hypothesized distribution.
- Does not depend on the grouping of data.
- Relatively insensitive to outlier points (i.e., distribution tails).
Geometric intuition
- K-S test is most useful when the sample size is small
- Geometric meaning of the test statistic:
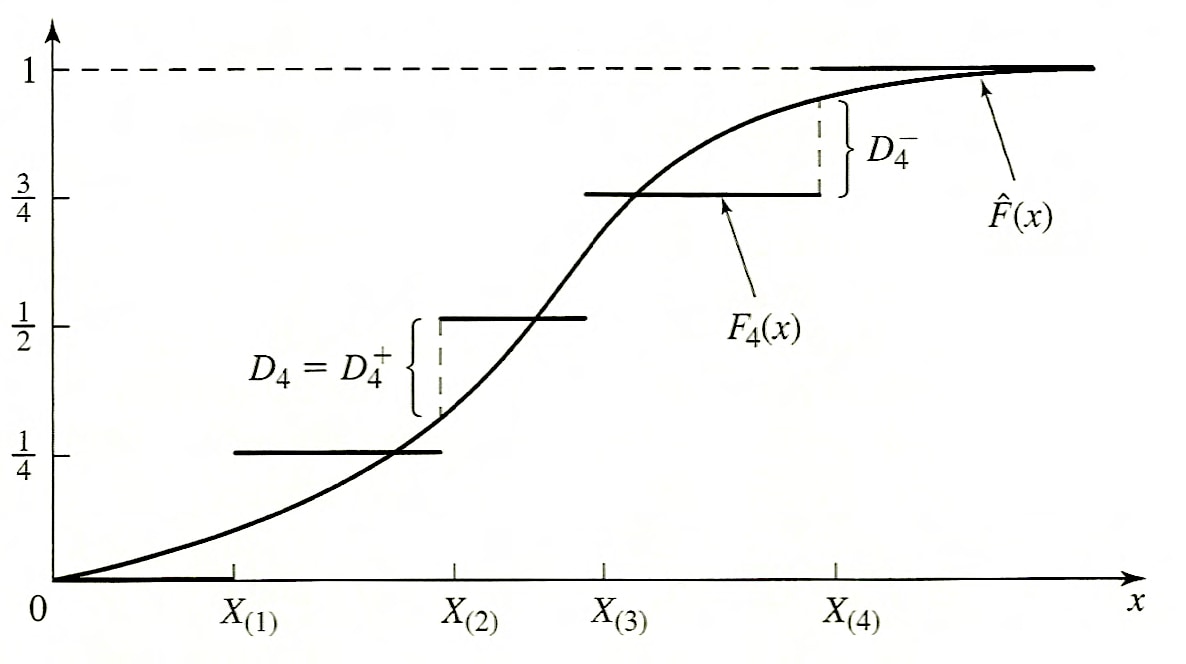
Test statistic
This is the operation that creates the sample distribution.
\[D_n^{+} = \max_{1\leq i\leq n} \left(\frac{i}{n} - \hat{F}(X_{(i)})\right)\] \[D_n^{-} = \max_{1\leq i\leq n} \left(\hat{F}(X_{(i)}) - \frac{i - 1}{n}\right)\] \[D_n = \max \left( D_n^{+}, D_n^{-} \right)\]
Not expressed in one equation with absolute value because distance is assessed from opposite ends for each.
How is this then converted to a p-value?
Graphical Analysis
Type I and Type II errors in hypothesis testing
- Type I error: error of rejecting \(H_0\) when it is true (false positive)
- Type II error: not rejecting \(H_0\) when it is false (false negative)
- Alpha: significance level; in the long run, \(H_0\) would be rejected falsely this fraction of the time (i.e., we are willing to accept an \(x\) fraction of false positives)
Beware of goodness-of-fit tests because they are unlikely to reject any distribution with little data, and are very sensitive to the smallest systematic error with lots of data.
Multiple hypotheses
We want to test whether gene expression differs between two cells more than would be expected by chance alone. We test the two samples with a p-value cutoff of 0.05:
- How many false positives would we expect after testing 20 genes?
- How about 1000 genes?
What about false negatives?
What does this mean when it comes to hypothesis testing?
Review
Reading & Resources
Review Questions
- \(p(x) = a/x\) for \(1 < x < 10\) describes a distribution pdf. What is \(a\)? What is the expression for the distribution mean?
- What are the three kinds of variables? Give an example of each.
- You are interested in the sample distribution of the mean for an exponential distribution (N=8). What can you say about it relative to the original one?
- What can you say about the sample distribution for the N=1 case?
- Studying an anti-tumor compound, you create 2 tumors in either flank (i.e. 1 mouse gets 2 tumors) of 5 mice, then treat the animals with a compound, measuring tumor growth. What is N? Justify your answer.
- You want to model a process where each successive outcome is 1/5 as likely (e.g., getting 3 is 1/5 as likely as getting 2). What is the expression for this distribution?