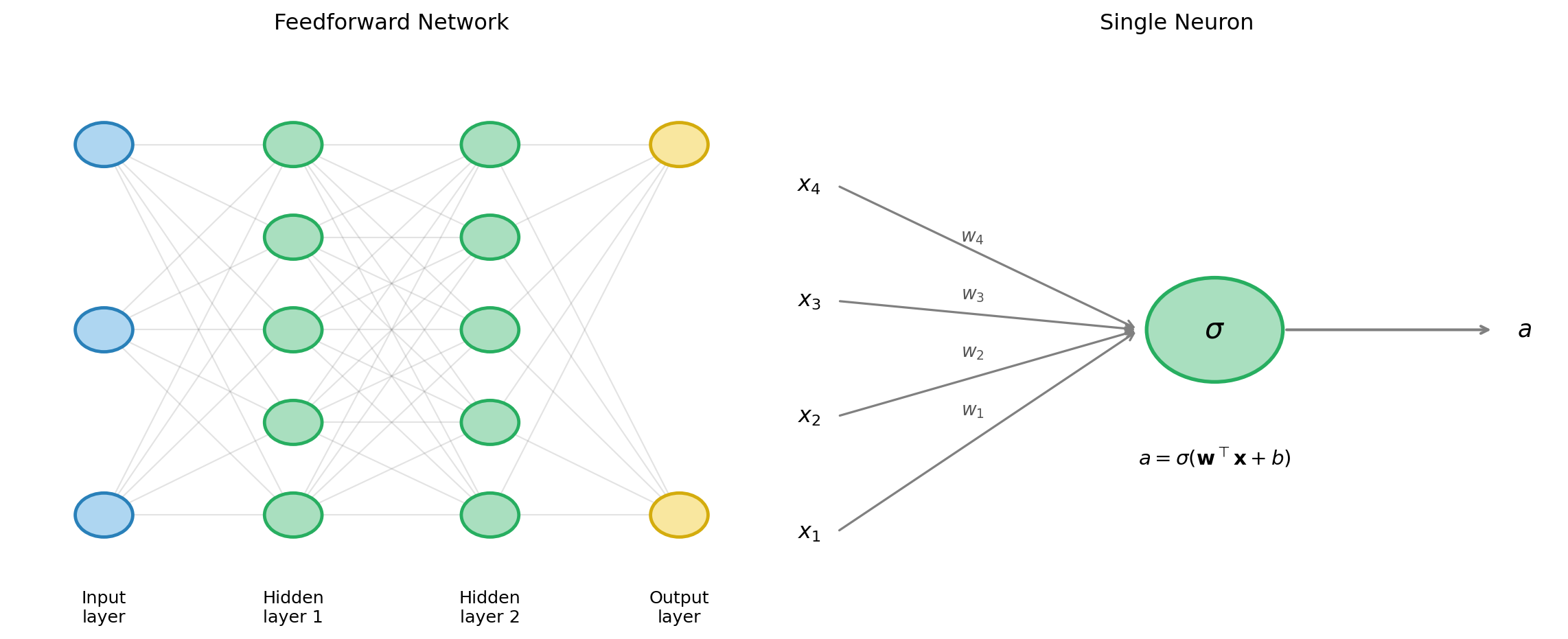
Neural Networks
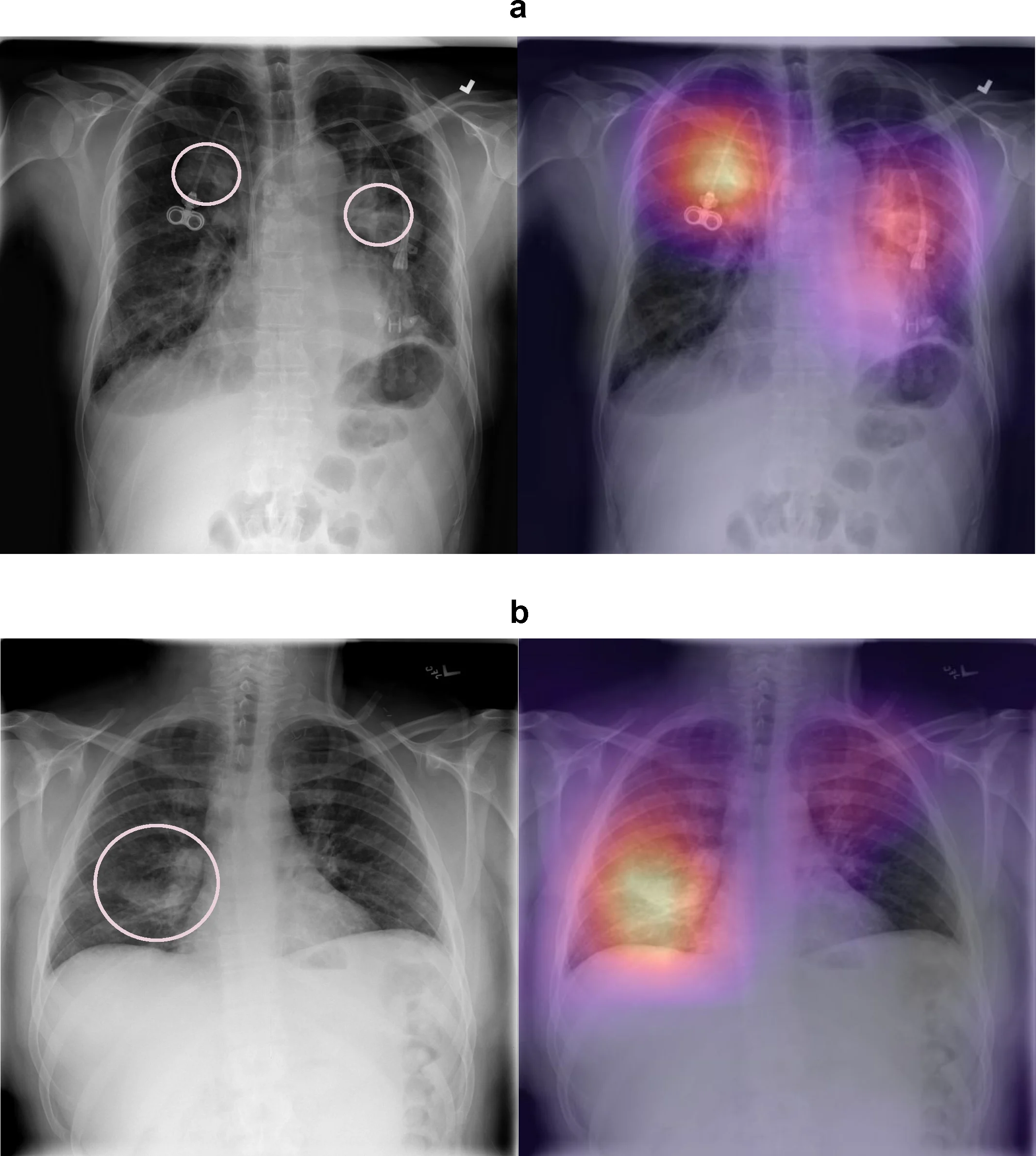
Figure 1: Model visualization of pneumothorax detection. (a) The model correctly identifies pneumothorax in the right and left upper lungs. (b) The model correctly identifies pneumothorax in the right lower lung. Figure from Taylor et al., PLOS Medicine (2018).
Activation Functions
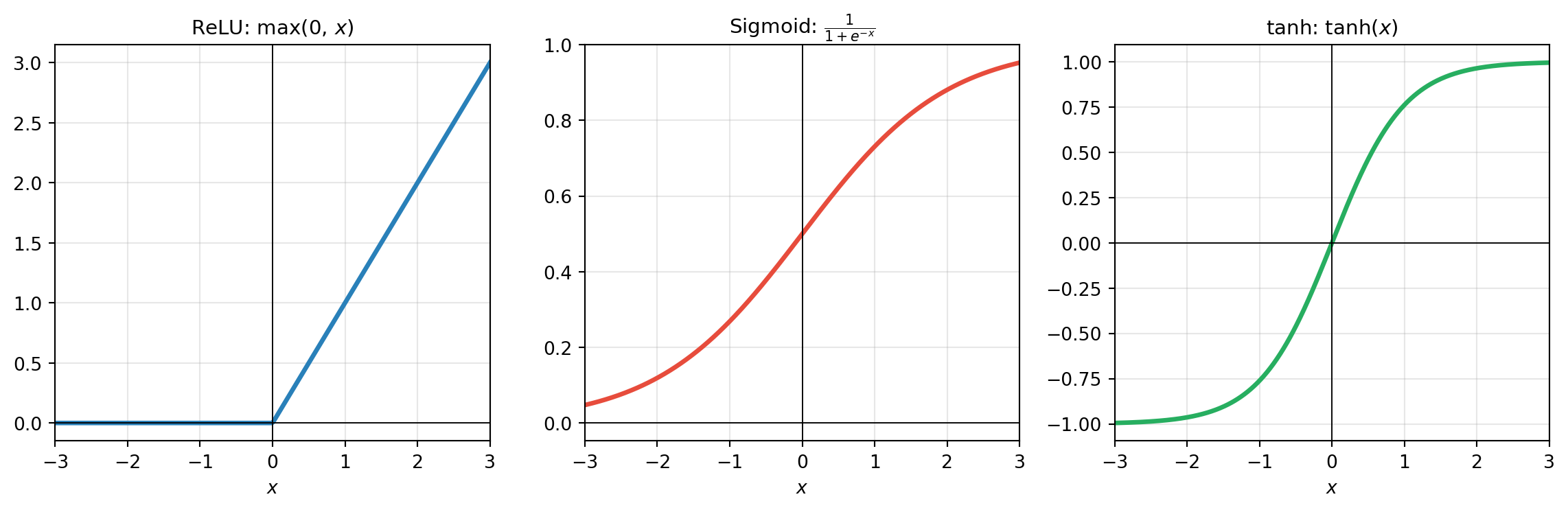
- ReLU (rectified linear unit): sparse, fast to compute, avoids vanishing gradient—the default choice for hidden layers
- Sigmoid: output in \((0,1)\)—useful for binary probability outputs
- tanh: output in \((-1,1)\)—zero-centered, often used in recurrent networks
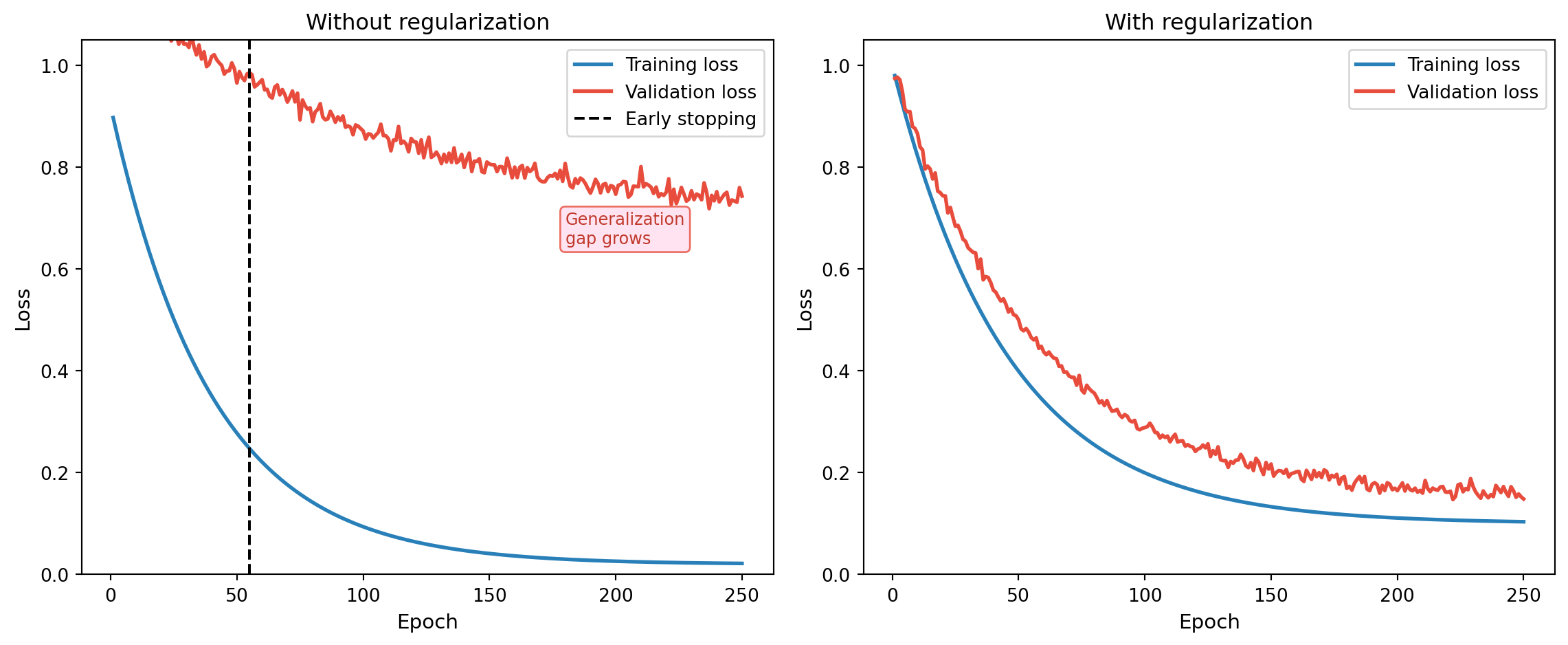
Training curves without and with regularization
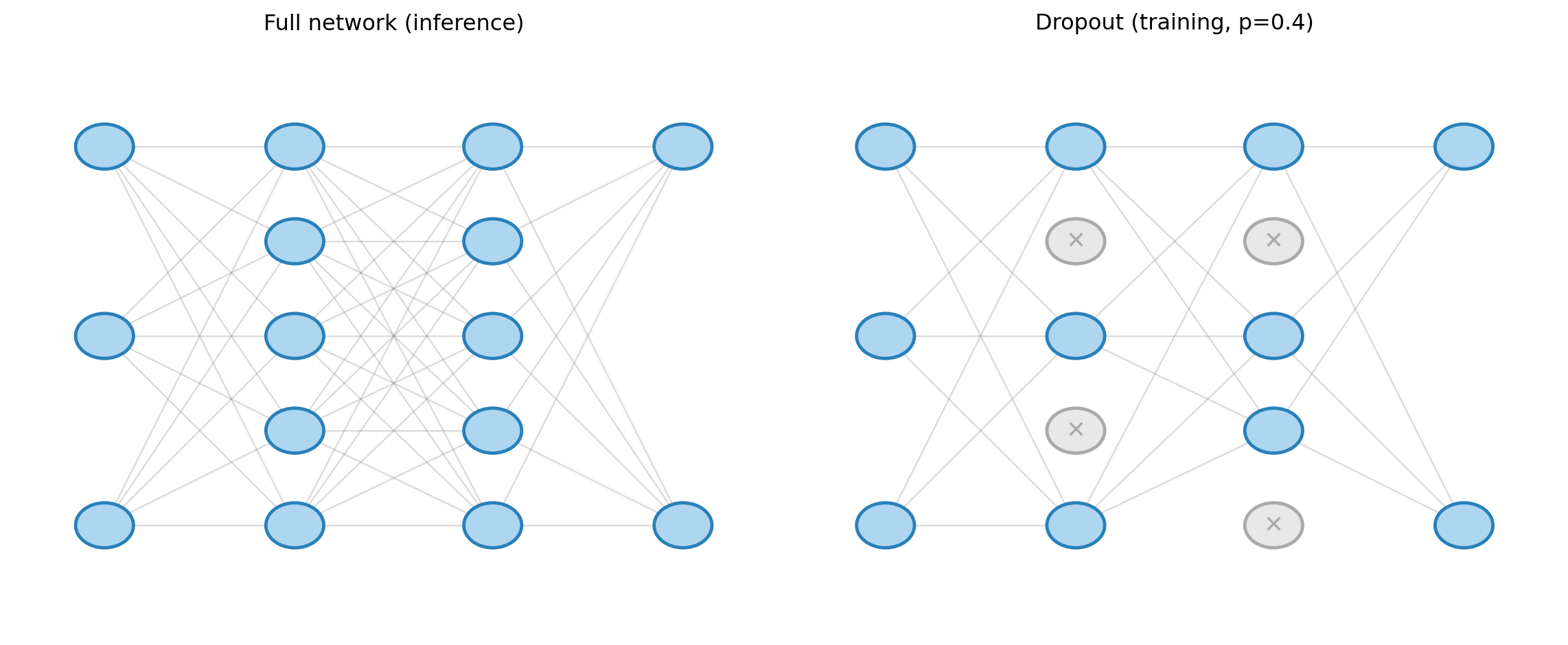
Dropout
- During each forward pass, randomly zero out a fraction \(p\) of neurons (Srivastava et al., 2014)
- At test time, scale all activations by \((1-p)\) to preserve expected magnitude
Convolutional Neural Networks (CNNs)
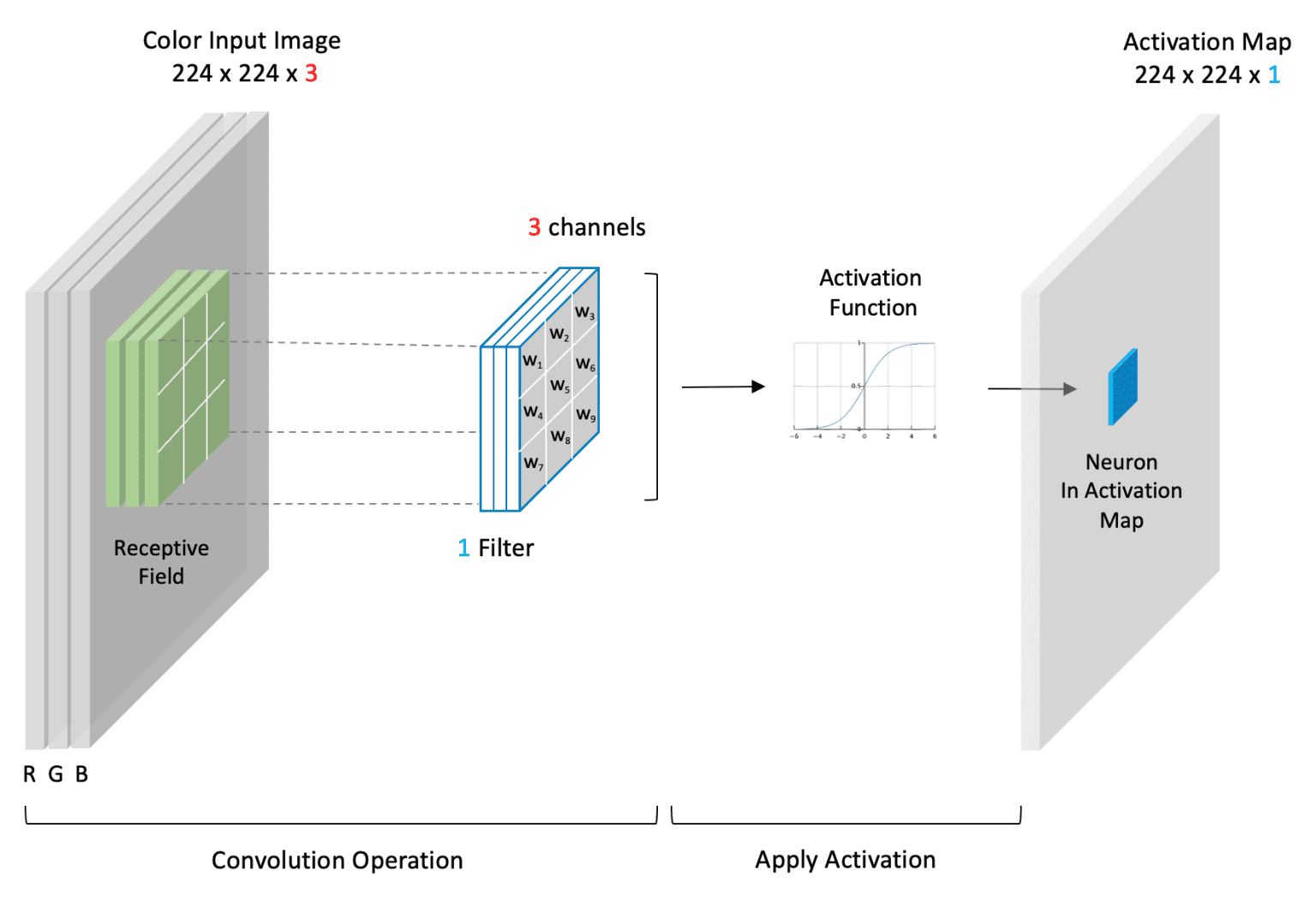
Figure 2: The convolution operation. A filter (or kernel) slides across the input image, computing a weighted sum of the local receptive field at each position to produce an activation map. Image credit: Bill Kromydas.
Graph Neural Networks (GNNs)
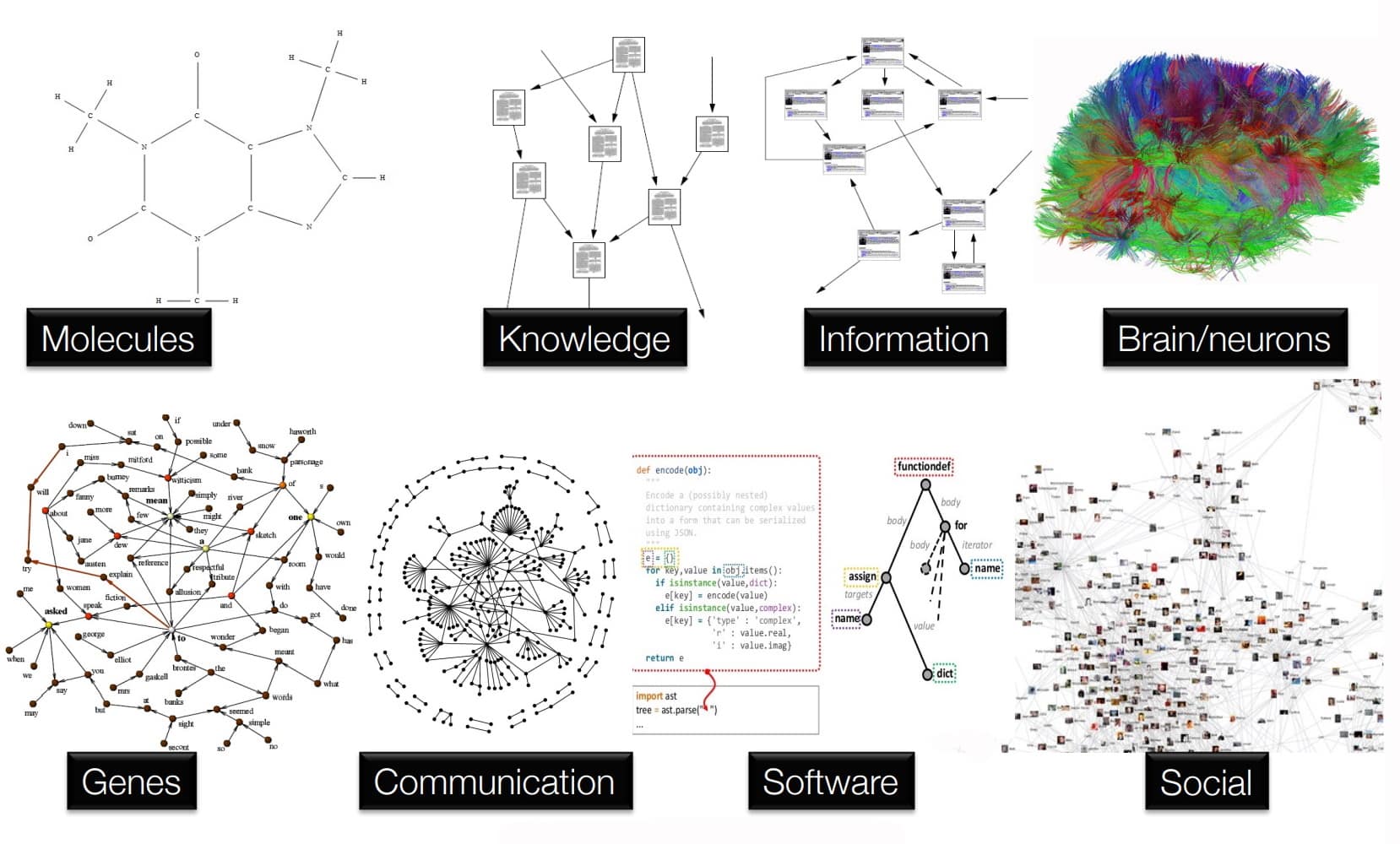
Figure 3: Examples of graph-structured data. Biology is full of relational structure, from molecular bonds and gene regulatory networks to the connectome. Image credit: Rick Merritt.
Attention and Transformers
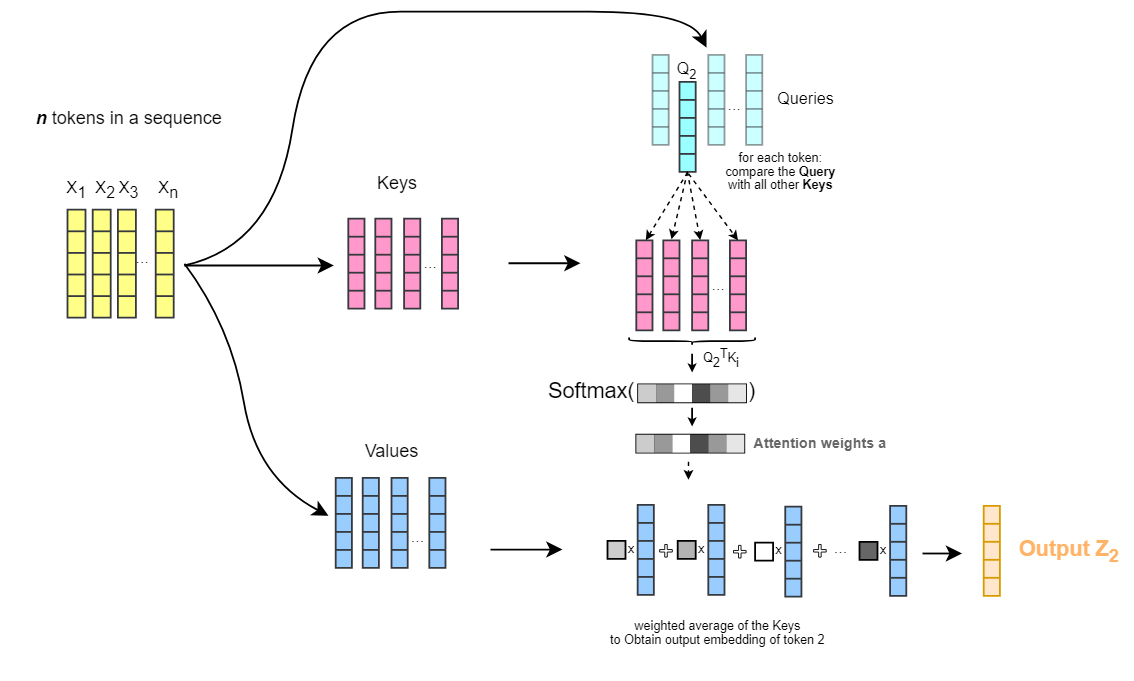
Figure 4: The attention mechanism. Input tokens are transformed into Queries (\(Q\)), Keys (\(K\)), and Values (\(V\)). The attention weights are computed by comparing Queries with Keys, then used to take a weighted average of Values. Image credit: Ebrahim Pichka.
Protein structure prediction: AlphaFold2
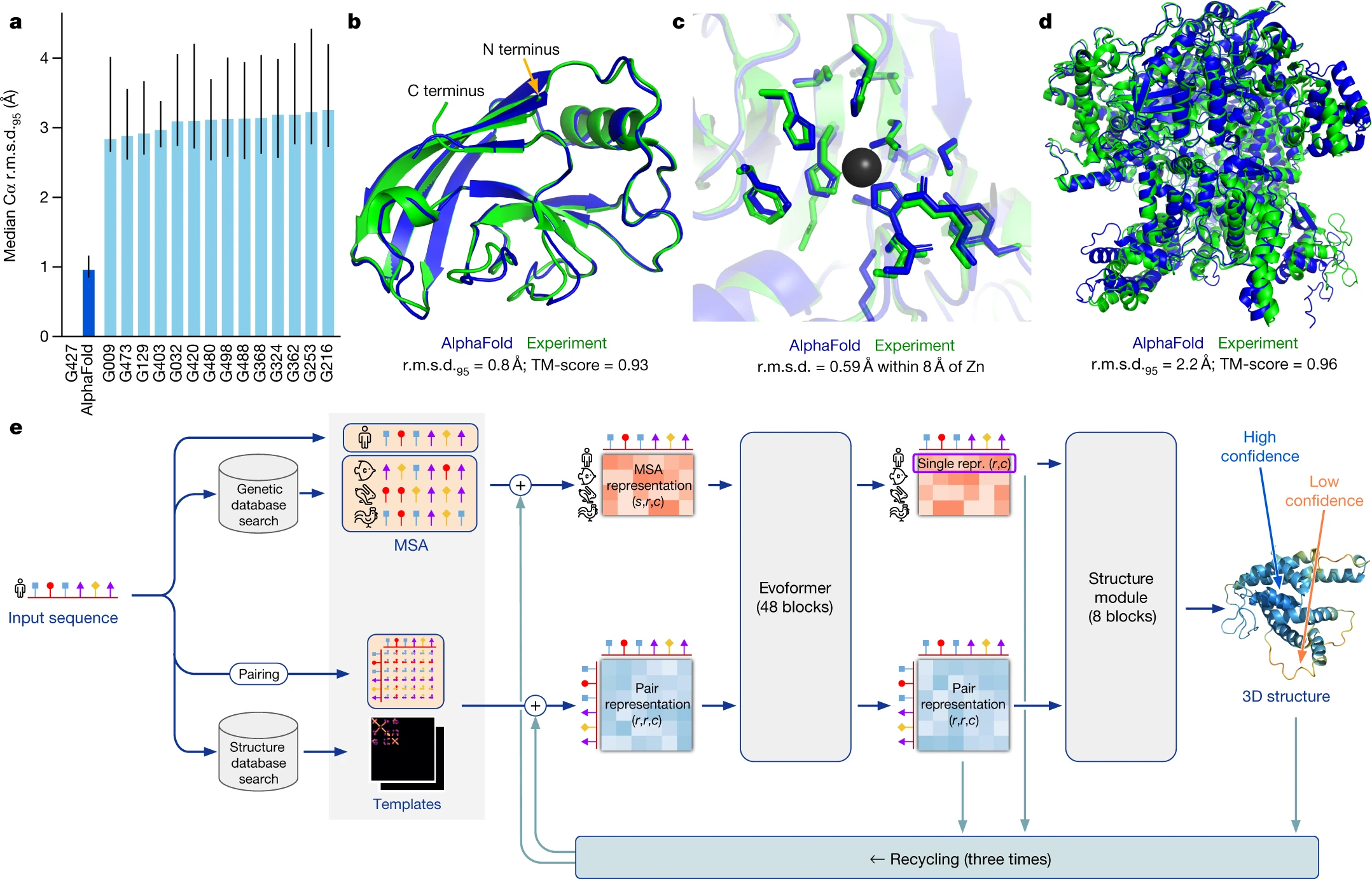
Figure 5: AlphaFold performance and architecture. (a) Competitive performance on CASP14 targets. (b–d) Examples of high-accuracy predictions (blue) compared to experimental structures (green), including complex domain packing and side-chain placement. (e) The model architecture, integrating MSA and template features through iterative recycling. Figure from Jumper et al., Nature (2021).
Cell morphology as a phenotypic readout
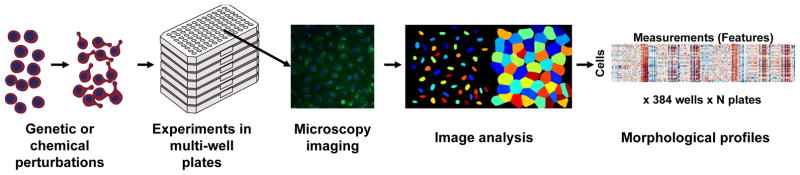
Figure 6: Cell Painting workflow. (a) Genetic or chemical perturbations are applied to cells in multi-well plates. (b) Cells are stained and imaged via microscopy. (c) Automated image analysis extracts morphological features. (d) Resulting morphological profiles are used for downstream tasks. Figure from Bray et al., Nature Protocols (2016).