Aaron Meyer & Yosuke Tanigawa (based on slides from Pam Kreeger)
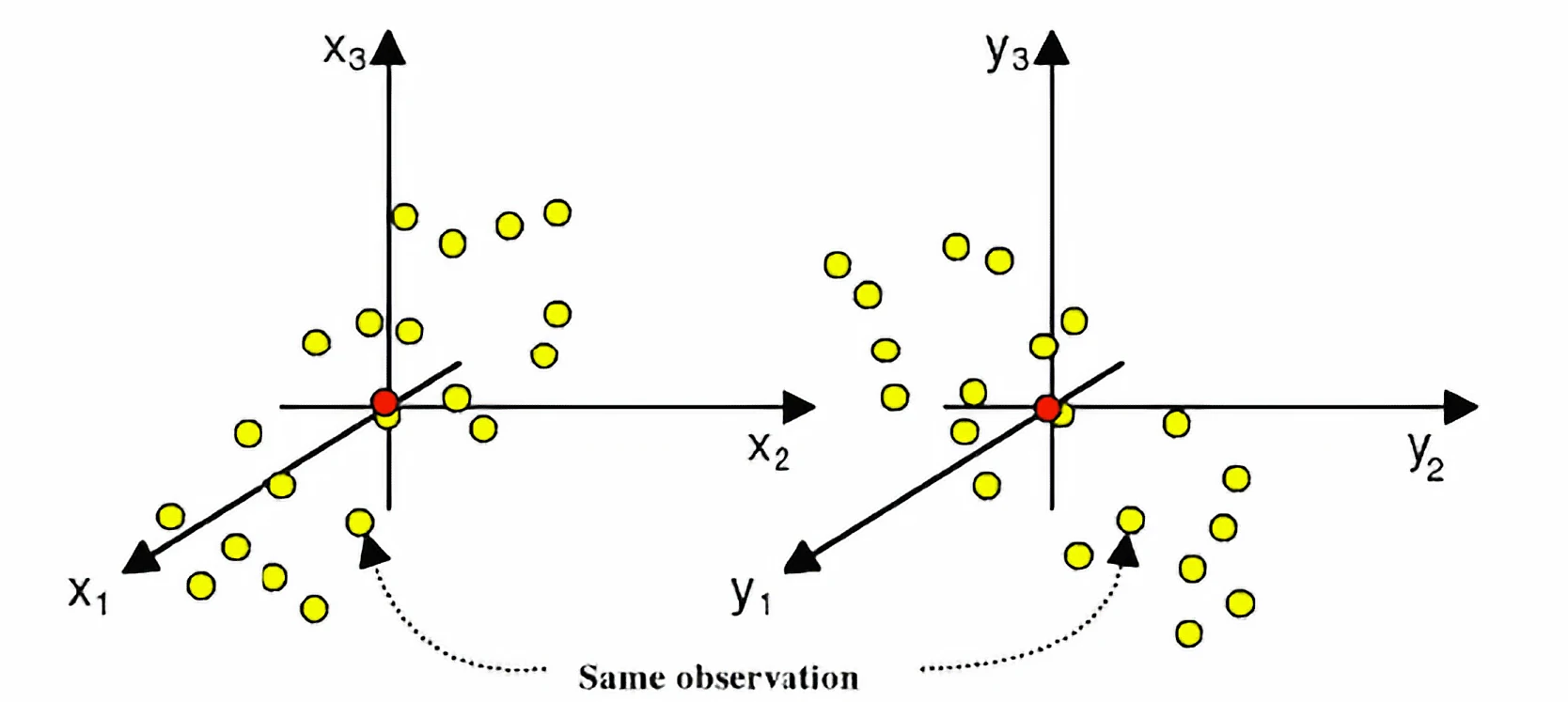
Common challenge: Finding coordinated changes within data
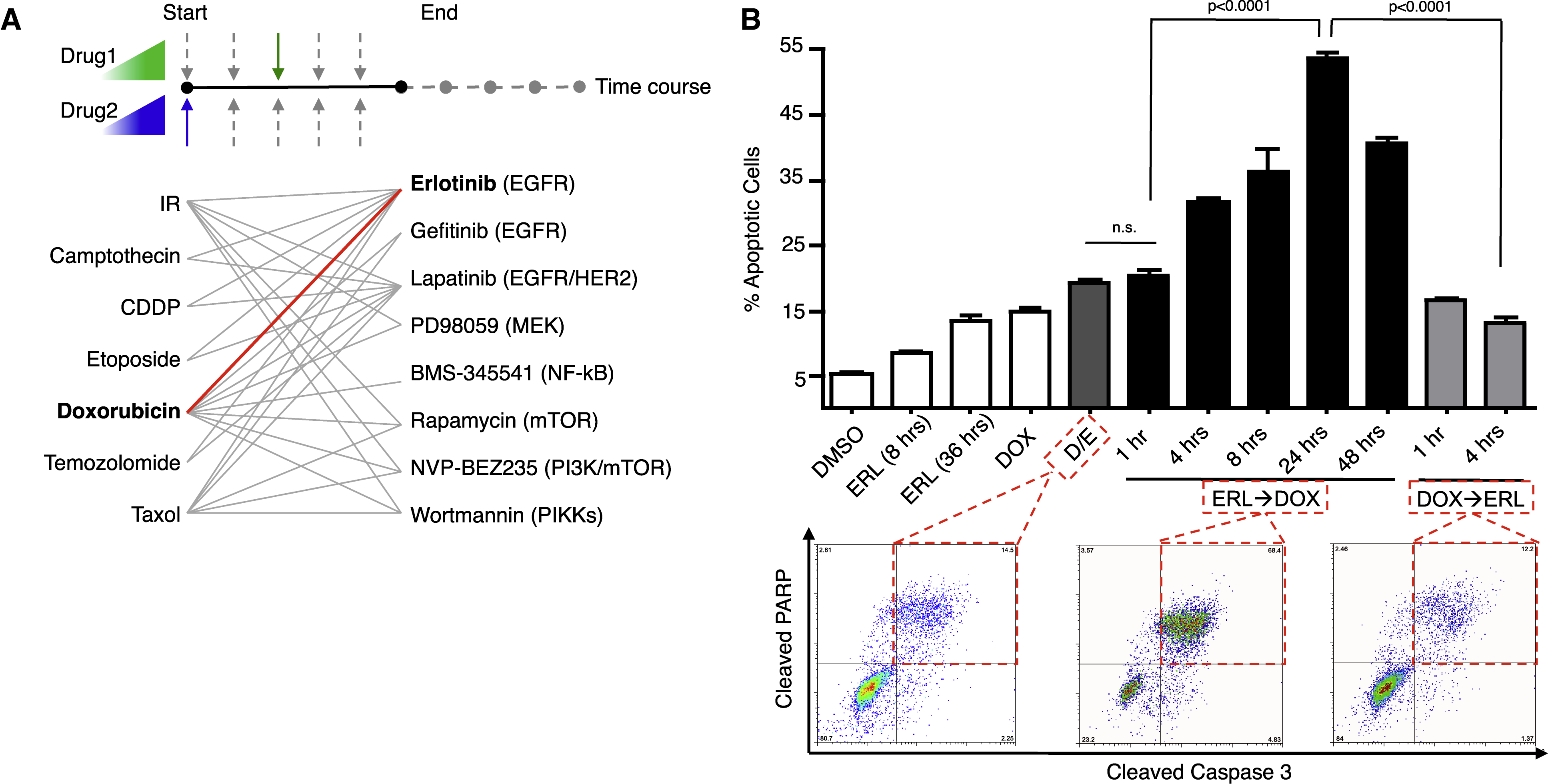
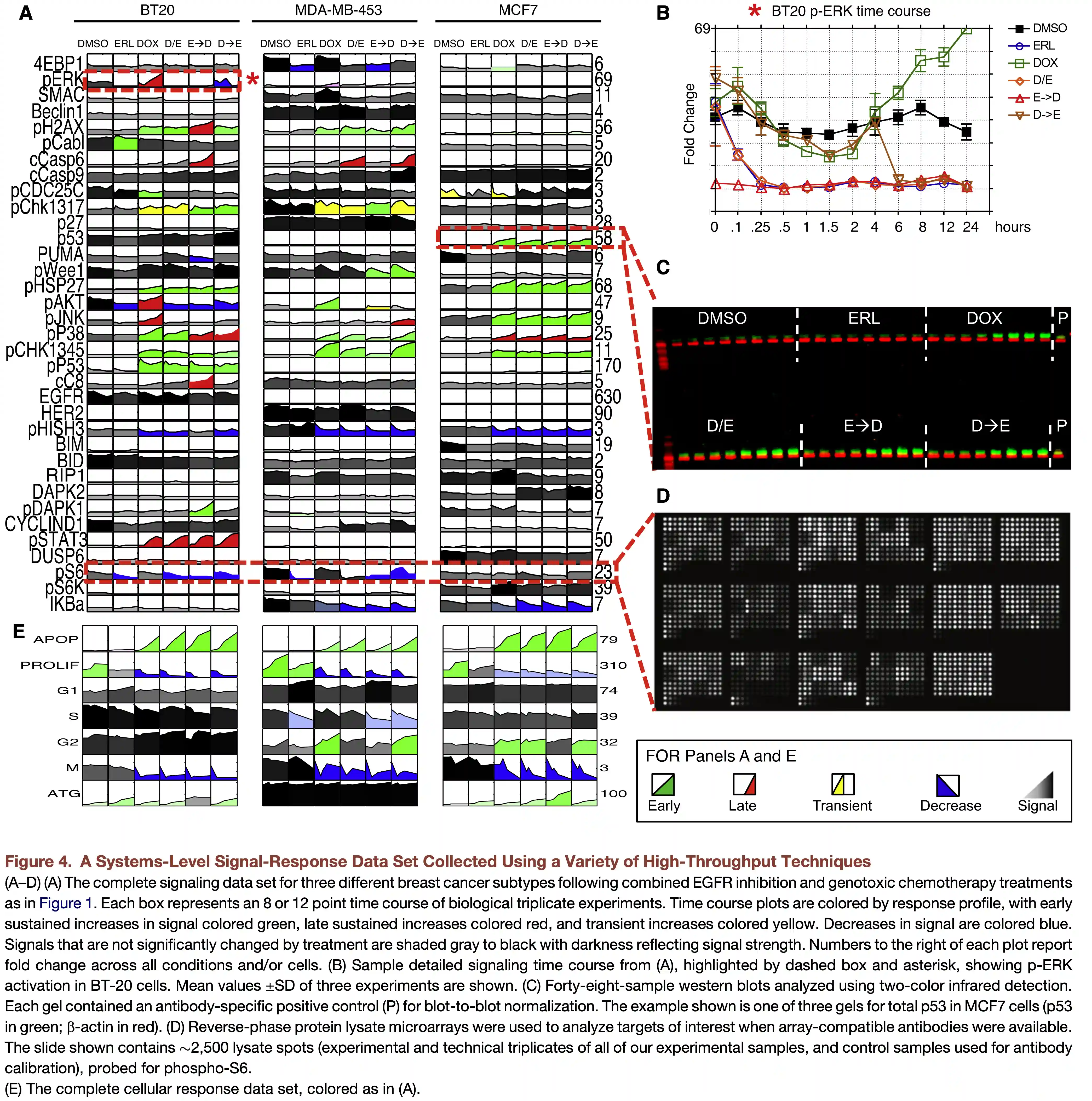
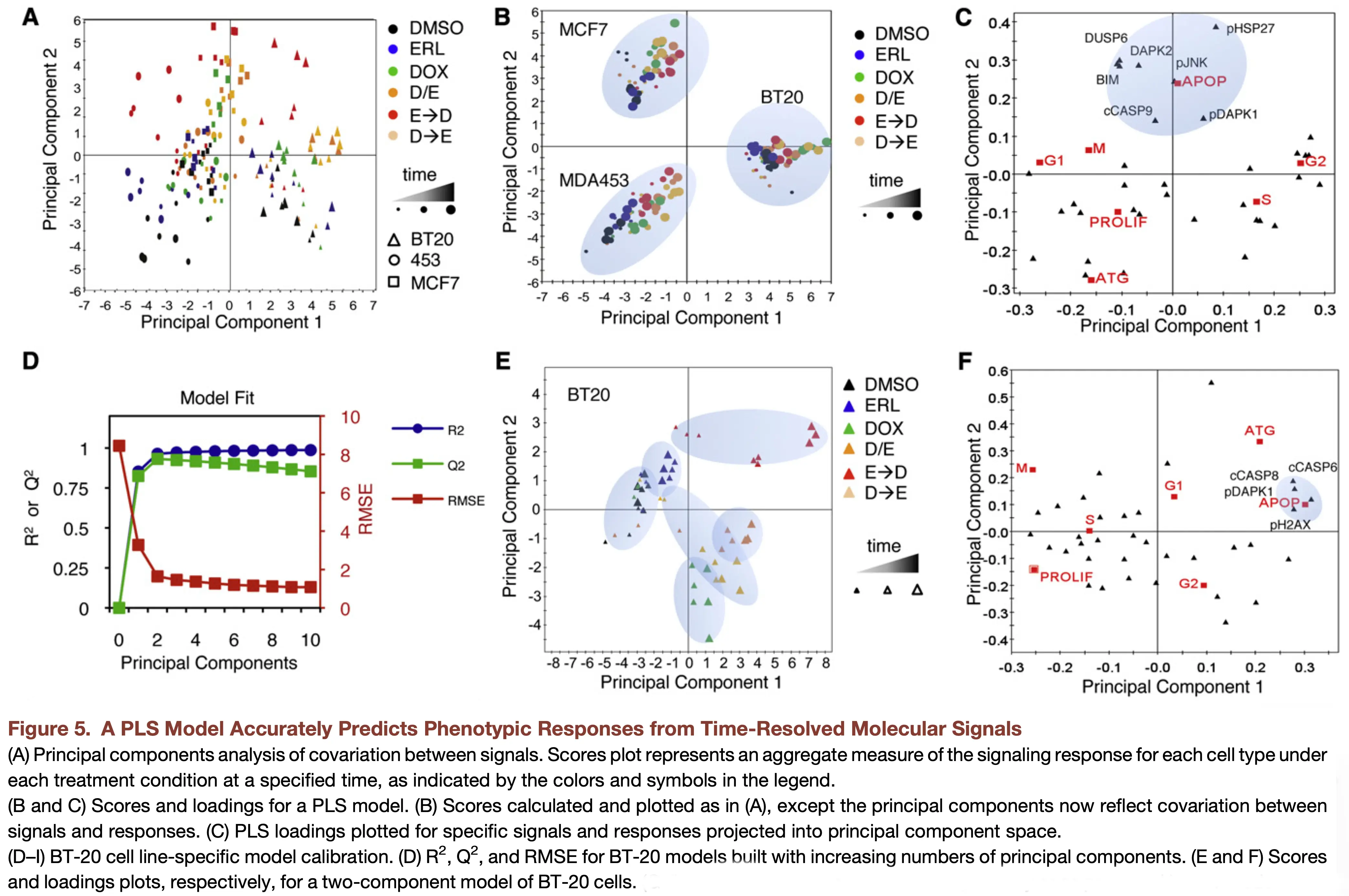
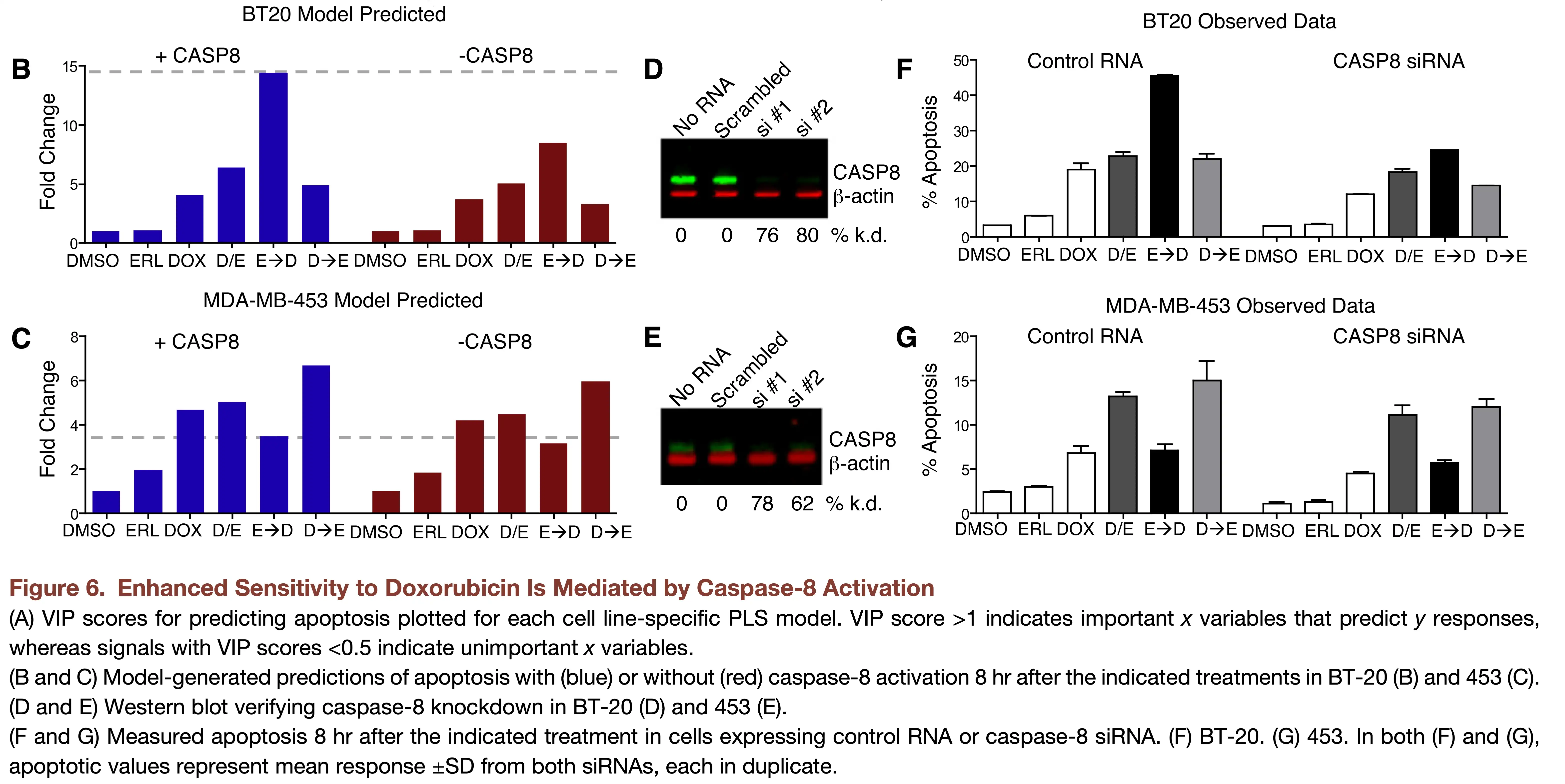
The timing and order of drug treatment affects cell death.
Notes about the methods today
We will cover two related methods today: principal components regression (PCR) and partial least squares regression (PLSR).
Both methods are used for supervised prediction; however, they have a number of distinct properties from other methods we will discuss.
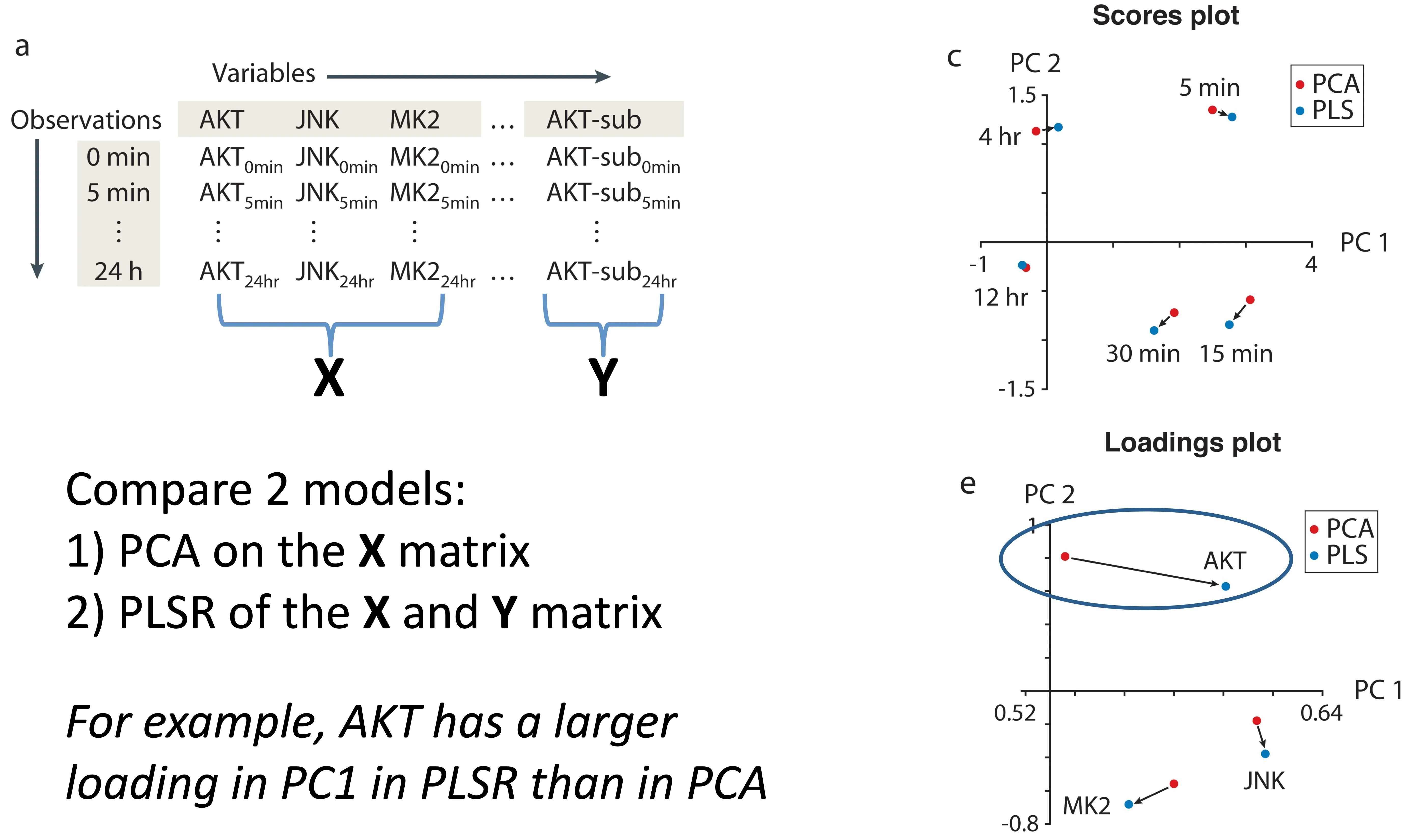
PCR constructs components using only \(\mathbf{X}\), while PLSR uses information from both \(\mathbf{X}\) and \(\mathbf{Y}\) when constructing latent directions.
Learning about PLSR is more difficult than it should be, partly because papers describing it span areas of chemistry, economics, medicine and statistics, with differences in terminology and notation.
Regularization
Both PCR and PLSR can act as forms of regularization.
Reduce the dimensionality of our regression problem to \(N_{\textrm{comp}}\) components.
Prioritize certain variance in the data.
Principal Components Regression (PCR)
Core idea
One solution: use the concepts from PCA to reduce dimensionality.
First step: Simply apply PCA!
Dimensionality goes from \(m\) to \(N_{\textrm{comp}}\).
Principal Components Regression
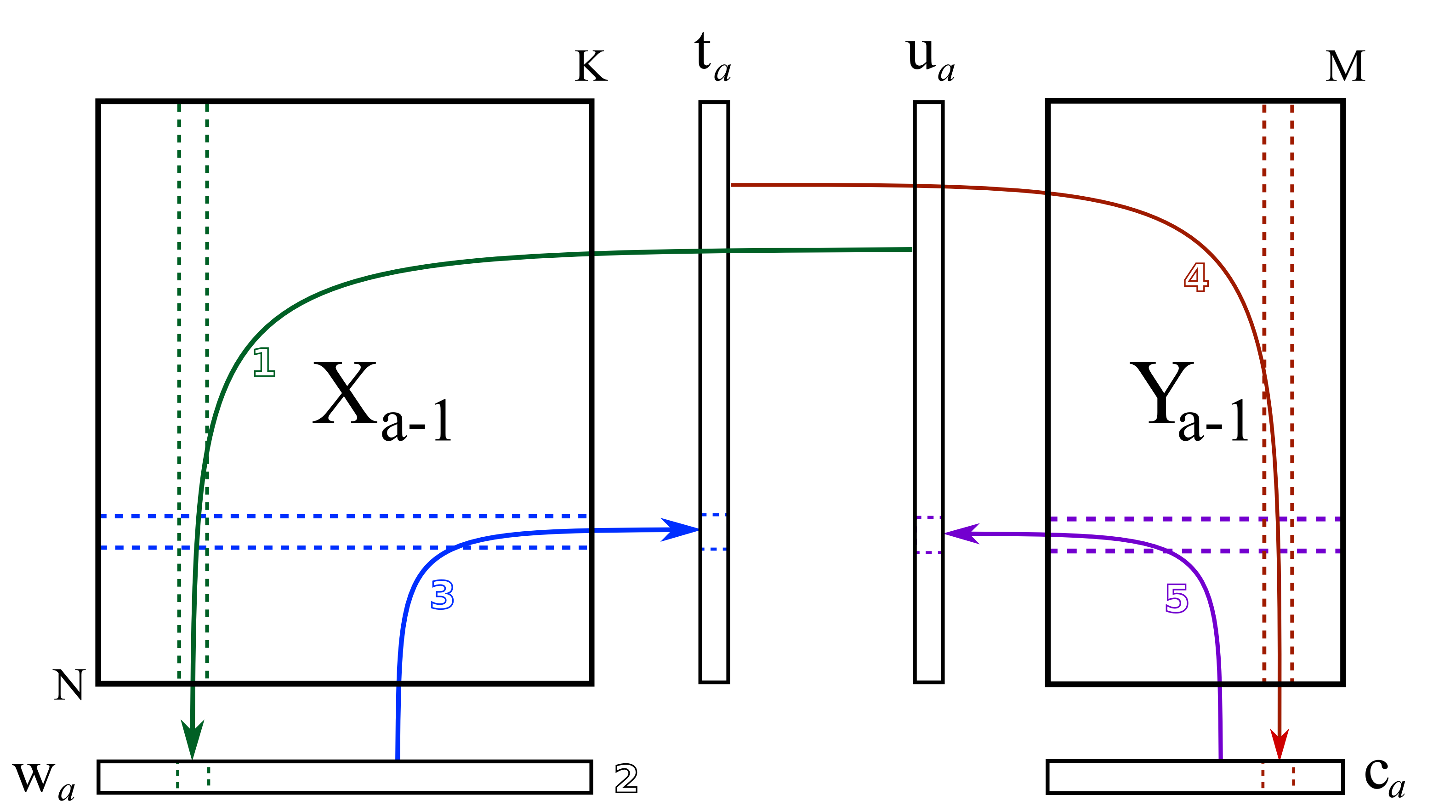
Decompose the \(\mathbf{X}\) matrix (scores \(\mathbf{T}\), loadings \(\mathbf{P}\), residuals \(\mathbf{E}_X\)):
How do we determine the right number of components to use for our prediction?
A remaining potential problem
The PCs for the \(\mathbf{X}\) matrix do not necessarily capture variation in \(\mathbf{X}\) that is important for \(\mathbf{Y}\).
Standard PCR can struggle when predictive signal lies in lower-variance directions.
There are a few developments around PCR that aim to improve prediction or interpretability.
Recent developments around PCR (advanced topics)
pcLasso: the LASSO meets PCR
pcLasso is a supervised regression method that combines sparsity with shrinkage toward leading principal-component directions.
It can be helpful when predictors are highly correlated and we want both good prediction and a smaller, more interpretable set of features.
Supervised PCA
Supervised PCA uses association with \(\mathbf{Y}\) to select features before performing PCA and regression.
It can help when many features are irrelevant to prediction.
Partial Least Squares Regression (PLSR)
The core idea of PLSR
What if, instead of choosing components based only on variance in \(\mathbf{X}\), we choose latent directions that maximize the covariance between scores derived from \(\mathbf{X}\) and \(\mathbf{Y}\)?
What is covariance?
Covariance measures how two variables vary together:
Cycle until convergence, then subtract off the variance explained by \(\widehat{\mathbf{X}}_a = \mathbf{t}_a\mathbf{p}_a^\top\) and \(\widehat{\mathbf{Y}}_a = \mathbf{t}_a \mathbf{c}_a^\top\).