Reproducible Computational Workflows
Aaron Meyer
Example - Genomics Annotations

Example - Genomics Annotations
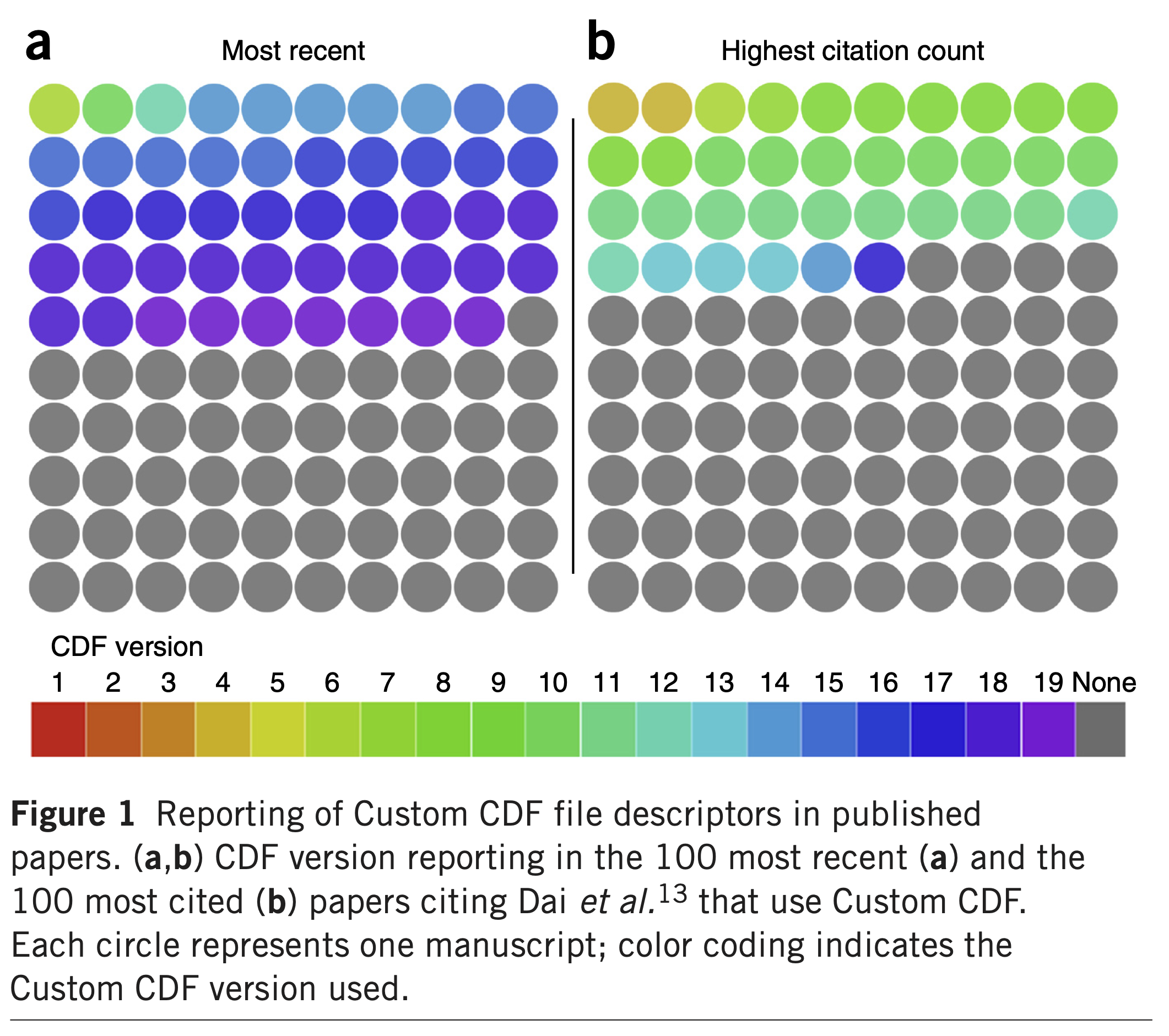
Example - Genomics Annotations
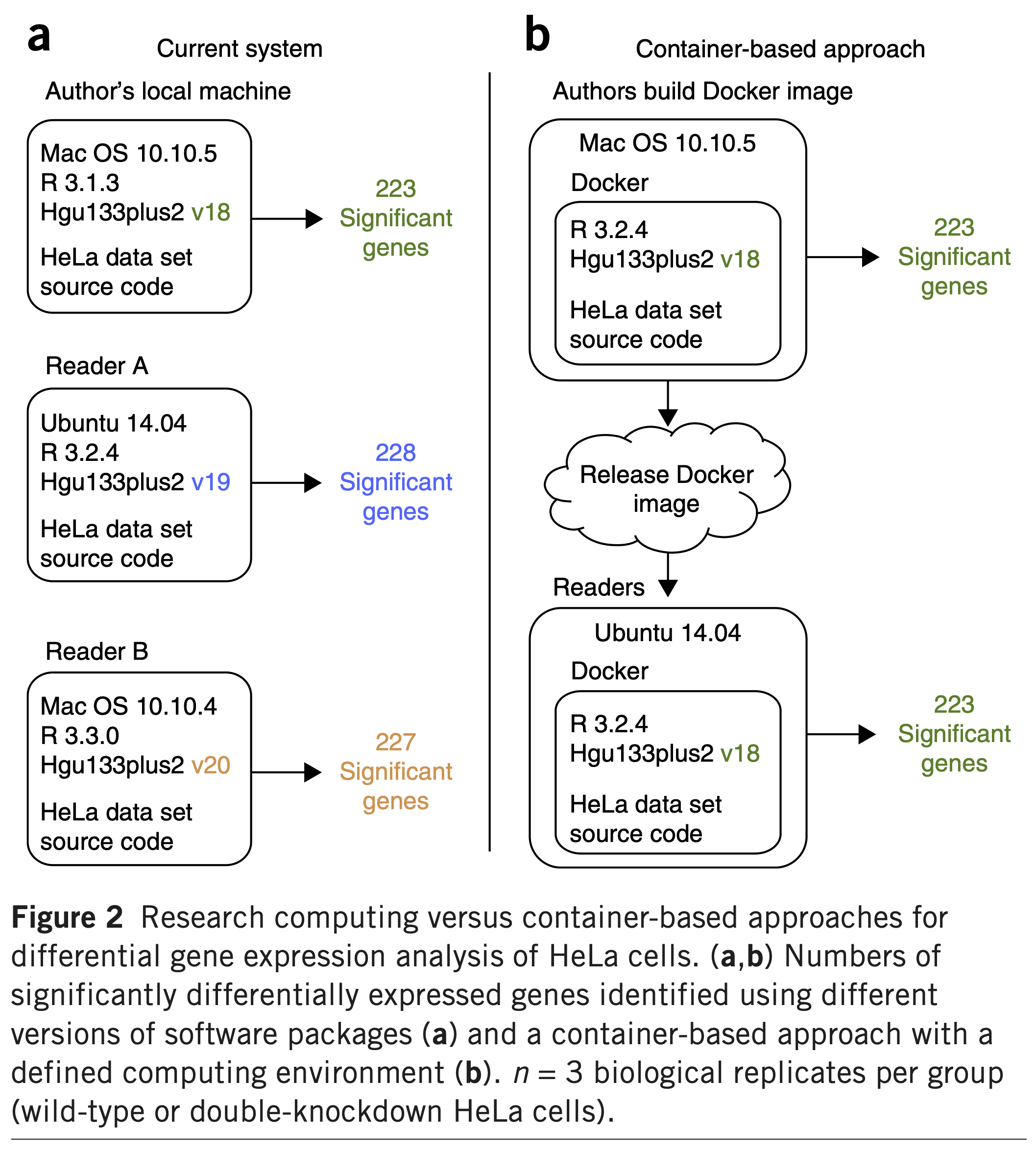
Example - Genomics Annotations
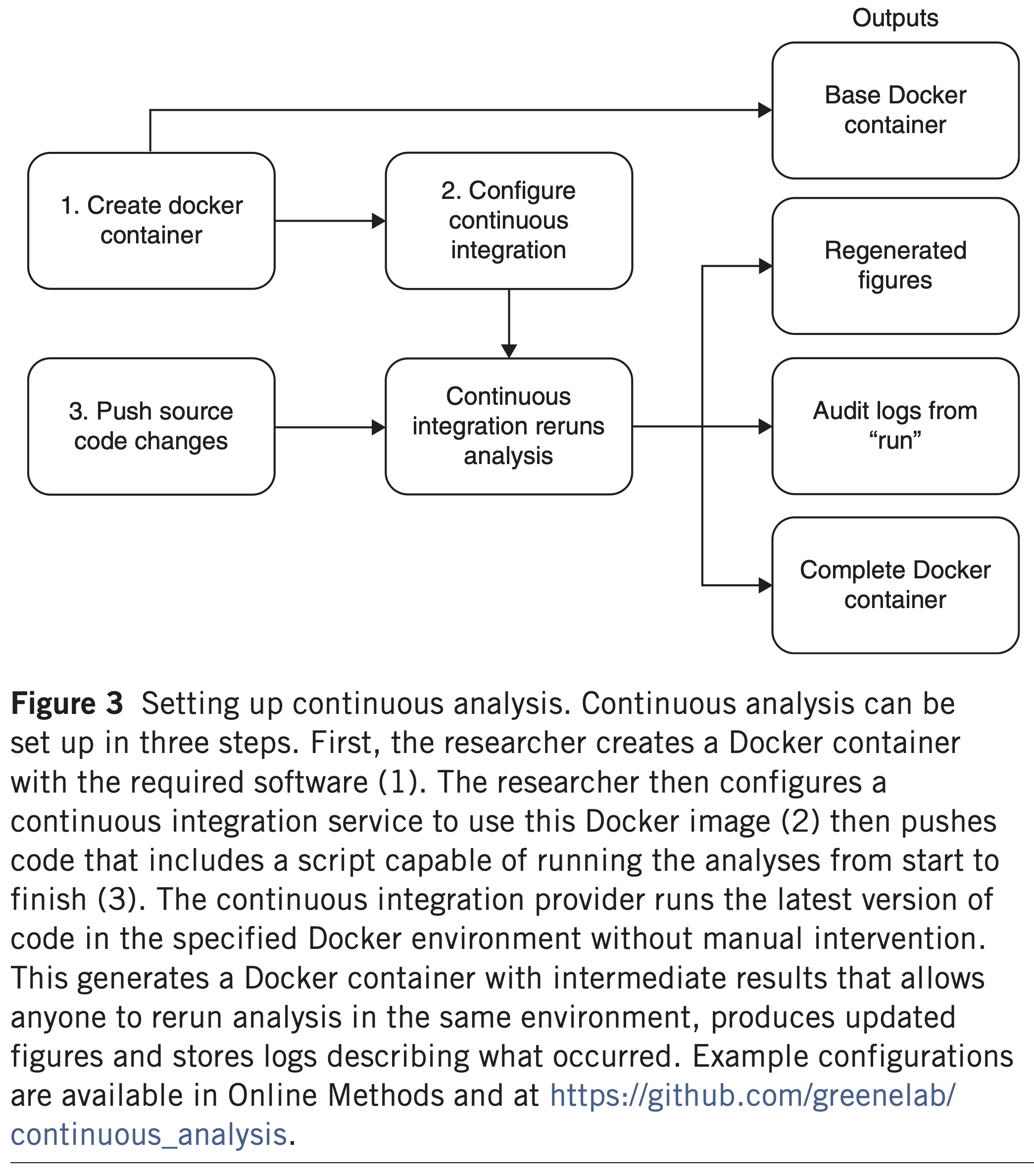
Example - Genomics Annotations
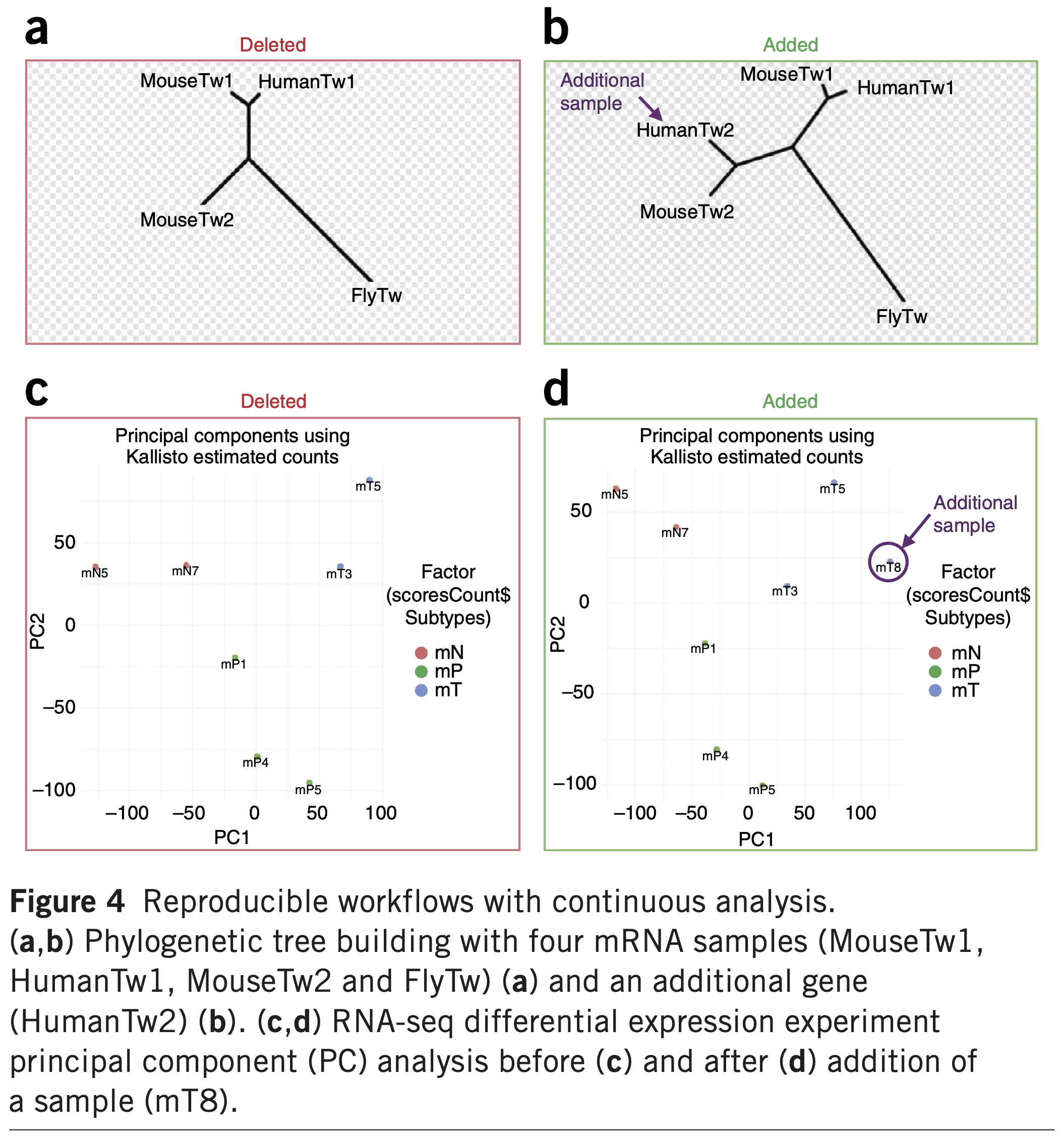
Bugs and Testing
- software reliability: Probability that a software system will not cause failure under specified conditions.
- Measured by uptime, MTTF (mean time to failure), crash data.
- Bugs are inevitable in any complex software system.
- Industry estimates: 10-50 bugs per 1000 lines of code.
- A bug can be visible or can hide in your code until much later.
- testing: A systematic attempt to reveal errors.
- Failed test: an error was demonstrated.
- Passed test: no error was found (for this particular situation).
Cost-benefit tradeoff
There is no one answer to testing
- You’re putting together a quick script to calculate the amount of a chemical you need
- You probably don’t need to test this
- You’re assembling a machine learning model to identify heart attacks
- Not testing this could be considered professional malpractice
Difficulties of testing
- Testing is seen as a novice’s job.
- Assigned to the least experienced team members.
- Done as an afterthought (if at all).
- “My code is good; it won’t have bugs. I don’t need to test it.”
- “I’ll just find the bugs by running the program.”
- Limitations of what testing can show you:
- It is impossible to completely test a system.
- Testing does not always directly reveal the actual bugs in the code.
- Testing does not prove the absence of errors in software.
Unit Testing
unit testing: Looking for errors in a subsystem (class, object, or function) in isolation.
The basic idea:
- For a given class
Foo, create another classFooTestto test it, containing various “test case” methods to run. - Each method looks for particular results and passes / fails.
- Put assertion calls in your test methods to check things you expect to be true. If they aren’t, the test will fail.
Python’s pytest
import pytest
import math
# Example function to test
def factorial(n):
if n < 0:
raise ValueError("Factorial not defined for negative numbers")
if n == 0:
return 1
else:
return n * factorial(n-1)
# Test for the example function
def test_factorial():
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(5) == 120
with pytest.raises(ValueError):
factorial(-1)Basic Assertions
pytest does not provide a large number of specific assertions. Instead, mostly use base assert.
Asserting Exceptions
There are specific approaches for special cases, like checking that exceptions do occur:
The documentation covers others, such as checking warnings. Numpy also has assertions for data vectors.
Setup and Teardown
import pytest
import pandas as pd
@pytest.fixture
def example_dataframe():
# Create a simple DataFrame for testing
data = {'col1': [1, 2, 3], 'col2': [4, 5, 6]}
df = pd.DataFrame(data)
return df
def test_dataframe_column_sum(example_dataframe):
# Test that the sum of 'col1' is correct
assert example_dataframe['col1'].sum() == 6
def test_dataframe_column_mean(example_dataframe):
# Test that the mean of 'col2' is correct
assert example_dataframe['col2'].mean() == 5.0Tips for Testing
- You cannot test every possible input, parameter value, etc.
- So you must think of a limited set of tests likely to expose bugs.
- Think about boundary cases
- positive; zero; negative numbers
- right at the edge of an array or collection’s size
- Think about empty cases and error cases
- 0, -1, null; an empty list or array
- test behavior in combination
- maybe add usually works, but fails after you call remove
- make multiple calls; maybe size fails the second time only
Trustworthy tests
- Test one thing at a time per test method
- 10 small tests are much better than 1 test 10x as large
- Each test method should have few (likely 1) assert statements
- If you assert many things, the first that fails stops the test
- You won’t know whether a later assertion would have failed
- Tests should avoid logic
- Minimize if/else, loops, switch, etc.
- Avoid try/catch
- If it’s supposed to throw, use assert for that
Torture tests are okay, but only in addition to simple tests.
Regression testing
- regression: When a feature that used to work, no longer works.
- Likely to happen when code changes and grows over time.
- A new feature/fix can cause a new bug or reintroduce an old bug.
- regression testing: Re-executing prior unit tests after a change.
- Often done by scripts during automated testing.
- Used to ensure that old fixed bugs are still fixed.
Many products have a set of mandatory check-in tests that must pass before code can be added to a source code repository.
Test-driven development
Test-driven development
Write tests, then write code to pass them.
- Unit tests can be written after, during, or even before coding.
Imagine that we’d like to add a method subtractWeeks to a Date class, that shifts this Date backward in time by the given number of weeks.
- Write code to test this method before it has been written.
- Then once we do implement the method, we’ll know if it works.
Things to avoid in unit tests
Tests should be self-contained and not care about each other.
Avoid:
- Constrained test order
- Test A must run before Test B.
- Usually a misguided attempt to test order/flow.
- Tests call each other
- Test A calls Test B’s method
- Calling a shared helper is OK, though
- Mutable shared state
- Tests A/B both use a shared object.
- If A breaks it, what happens to B?
Testing summary
- Tests need failure atomicity (ability to know exactly what failed).
- Each test should have a clear, long, descriptive name.
- Assertions should always have clear messages to know what failed.
- Write many small tests, not one big test.
- Each test should have roughly just a couple assertions at its end.
- Test for expected errors / exceptions.
- Choose a descriptive assert method, not always assertTrue.
- Choose representative test cases from equivalent input classes.
- Avoid complex logic in test methods if possible.
- Use helpers, setup functions to reduce redundancy between tests.
Failure consistency
- Tests should consistently pass or fail.
- Inconsistent tests are hard to fix, and easy to miss.
- Avoiding these is very difficult for iterative methods.
Reproducible builds
- One element that unit testing highlights is the contribution of randomness
- For example, if we start optimization at a random point, something might just break 1% of the time
- This makes it challenging to identify when something breaks
- Often, to avoid this, random number generators are set to a constant seed
- But, keep in mind this then only tests one outcome of this value
Reproducible builds
- Other source of variation: the code surrounding your analysis
- E.g.
seabornpackage changes the way it orders colors on a graph - A solution to this is
uv, a modern Python package manager- Creates an isolated virtual environment for your project
- Pins exact versions of all dependencies in a lockfile (
uv.lock) - Much faster than older tools like
piporvirtualenv
- Projects using
uvhave apyproject.tomlfile- Declares the project’s dependencies and metadata
- The
uv.locklockfile records exact versions of every package, ensuring anyone running the project gets the same environment
- E.g.
Containerization
- What about Linux vs. Windows vs. MacOS differences? Time differences? “Gremlins”?
- Way to get around this variability is to make sure everything else in the environment stays constant
- One way to do this is with a container
- E.g. docker, which downloads and runs a virtual machine
- Essentially you start up a “virtual computer”, then install everything you need
- Dev containers: VS Code Dev Containers and GitHub Codespaces provide a more accessible entry point
- Define your entire development environment in a
.devcontainer/config file - Anyone opening the project gets the same environment automatically
- Define your entire development environment in a
Integration testing
- integration: Combining two or more software units
- often a subset of the overall project (!= system testing)
- Why do software engineers care about integration?
- new problems will inevitably surface
- many systems now together that have never been before
- if done poorly, all problems present themselves at once
- hard to diagnose, debug, fix
- cascade of interdependencies
- cannot find and solve problems one-at-a-time
- new problems will inevitably surface
Two Approaches To Integration
- phased (“big-bang”) integration:
- design, code, test, debug each class/unit/subsystem separately
- combine them all
- hope it all comes together
- incremental integration:
- develop a functional “skeleton” system
- design, code, test, debug a small new piece
- integrate this piece with the skeleton
- test/debug it before adding any other pieces
Benefits Of Incremental
- Benefits:
- Errors easier to isolate, find, fix
- reduces developer bug-fixing load
- System is always in a (relatively) working state
- Errors easier to isolate, find, fix
- Drawbacks:
- May need to create “stub” versions of some features that have not yet been integrated
- Not always possible
When To Build
- daily build: Compile working executable on a daily basis
- allows you to test the quality of your integration so far
- helps morale; product “works every day”; visible progress
- best done automated or through an easy script
- quickly catches/exposes any bug that breaks the build
- smoke test: A quick set of tests run on the daily build.
- NOT exhaustive; just sees whether code “smokes” (breaks)
- used (along with compilation) to make sure daily build runs
- continuous integration:
- Automatically running tests on every commit, typically via a service like GitHub Actions.
- Catches bugs early and ensures the codebase stays in a working state.
Associated topics & tools
Property-based testing
- Property-based testing is a slight variant of unit testing
- Rather than specifying an exact program to run, you specify some properties that should hold
- e.g. if
C = f(A, B),C > BandC > A
- Methods exist to test whether this is true, and do it in a way that is more efficient than trying random values
hypothesisis a python package for this
Fuzzing
- Let’s say you have a function that reads in some random data from the internet then processes it
- You want to make sure it won’t crash no matter what’s sent to it
- Fuzzing is the process of sending all sorts of random data to a program, to make sure it keeps working
- “Working” can be not crashing, but also that you still get some proper output
- Tools like afl (American Fuzzy Lop) can peer into your program to actively look for random inputs to make it behave differently
- Packages like
datafuzzcan perform the data equivalent—i.e. add noise, etc, that shouldn’t influence the analysis
Linting
- It’s possible to write a program that is correct and runs, but just isn’t written well
- E.g. Hard to read
- Fails to follow best practices
- The interpreter/compiler figures it out, but it’s a bad idea
- For example:
pythonfunctioniwrotemyselfonasundayafterwaytoomuchcoffee(argument = False) - Linters are programs to check various rules about how code should be written
- Can also use static analysis to determine potential errors
ruffis the modern standard for Python linting and formatting- Replaces both
pylint(linter) andblack(formatter) in a single, extremely fast tool - Catches style issues, unused imports, potential bugs, and enforces consistent formatting
- Replaces both
Code review
- Code review is when someone else looks at your code
- Can be informal, or part of a formal process
- Goal is to identify bugs, improve code quality, and transfer knowledge
- Can be done before or after code is committed
- AI-assisted review (GitHub Copilot, Claude, etc.) is now mainstream and widely used in production
- Useful for catching surface-level issues quickly, but can miss logic errors, domain-specific correctness, or security flaws
- Human review remains essential for critical code paths
- Some companies require code review for all code
- Can be a good way to catch errors, and ensure code quality
Reproducibility in Machine Learning
Random seeds and non-determinism
- Many ML workflows involve randomness: weight initialization, data shuffling, dropout, etc.
- Setting a random seed (
numpy.random.seed,torch.manual_seed) controls this - But GPU operations can still be non-deterministic even with seeds set
- A seed only tests one outcome — make sure results are robust across seeds
- Setting a random seed (
Data and model versioning
- Code isn’t the only thing that changes — datasets and model checkpoints do too
- DVC (Data Version Control) tracks datasets and model artifacts alongside code
- Works like git for large files, storing metadata in the repo and data in remote storage
- Lets you reproduce any past result by checking out a specific version of both code and data
Notebook reproducibility
- Jupyter notebooks are common in research and bioinformatics, but have a reproducibility trap:
- Cells can be run out of order, leaving hidden state in memory
- A notebook that “works” interactively may fail when run top-to-bottom
- Best practices:
- Always test notebooks by restarting the kernel and running all cells in order
nbstripoutremoves output and execution counts from notebooks before committing to gitpapermillcan execute notebooks programmatically as part of a pipeline
Summary
- For complex analysis make sure to use unit testing
- Exactly what testing is necessary or helpful depends on the problem at hand
- More testing isn’t as important as better testing
- For multi-part problems, it’s important to think of all the factors affecting your outcome
Further Reading
unittest, the built-in python testing frameworkpytest, a package to run small, readable testshypothesis, a python package for property-based testingruff, a modern python linter and formatteruv, a modern Python package and environment managerdvc, data version control for ML datasets and model artifactspapermill, parameterizing and executing Jupyter notebooks
Review Questions
- Who/what sort of people need to test their code?
- What is the difference between unit tests and integration tests?
- What does testing guarantee?
- What is the difference between testing and fuzzing?
- What is linting?
- You and a colleague are putting together a model. What are some factors that could influence the results besides the code that you write?
- You write a function that takes in a voltage from a device and returns the inferred heart rate of the measured individual. What are three high-quality unit tests you could write to test this?